En el acelerado panorama actual de la inteligencia artificial (IA), entrenar grandes modelos de lenguaje (LLMs) presenta desafíos significativos. Estos modelos a menudo requieren recursos computacionales enormes y una infraestructura sofisticada para manejar las vastas cantidades de datos y algoritmos complejos que conllevan. Sin un marco estructurado, el proceso puede volverse prohibitivamente lento, costoso y complejo. Las empresas luchan con la gestión de cargas de trabajo de entrenamiento distribuidas, la utilización eficiente de recursos y la precisión y rendimiento del modelo. Aquí es donde entra en juego el NVIDIA NeMo Framework.
NVIDIA NeMo es un marco integral basado en la nube para entrenar y desplegar modelos de IA generativa con billones de parámetros a gran escala. Este marco proporciona un conjunto completo de herramientas, scripts y recetas para apoyar cada etapa del viaje de los LLM, desde la preparación de datos hasta el entrenamiento y despliegue. Ofrece una variedad de técnicas de personalización y está optimizado para la inferencia a gran escala de modelos tanto para aplicaciones de lenguaje como de imágenes, utilizando configuraciones multi-GPU y multinodo. NVIDIA NeMo simplifica el desarrollo de modelos de IA generativa, haciéndolo más rentable y eficiente para las empresas. Al proporcionar pipelines de extremo a extremo, técnicas avanzadas de paralelización, estrategias de ahorro de memoria y checkpointing distribuido, NVIDIA NeMo asegura que el entrenamiento del modelo de IA sea fluido, escalable y de alto rendimiento.
El tren de beneficios al utilizar NVIDIA NeMo para el entrenamiento distribuido incluye:
– Pipelines de extremo a extremo para distintas etapas como la preparación de datos y el entrenamiento, permitiendo un enfoque plug-and-play para datos personalizados.
– Técnicas de paralelización que incluyen paralelismo de datos, tensor, pipeline, secuencia, experto y contexto.
– Técnicas de ahorro de memoria como el recompute selectivo de activaciones, offloading en CPU, y varias optimizaciones de atención y optimizadores distribuidos.
– Cargadores de datos para diferentes arquitecturas y checkpointing distribuido.
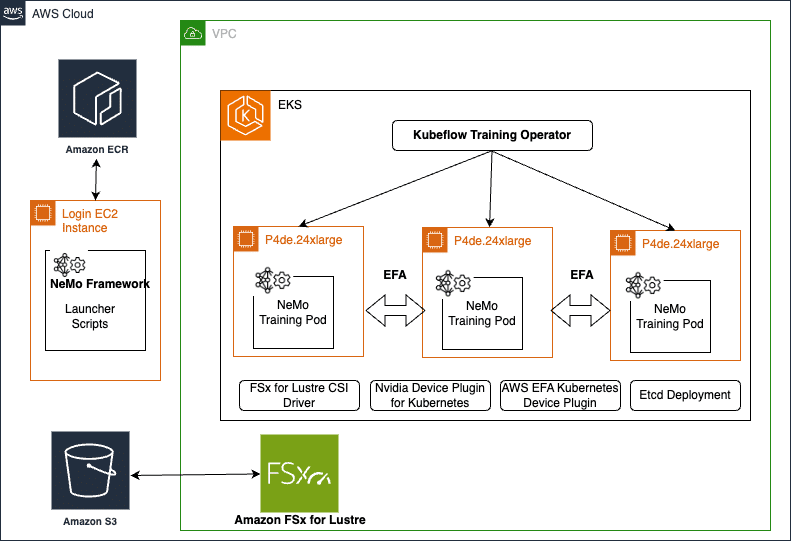
La solución se puede desplegar y gestionar utilizando plataformas de orquestación como Slurm o Kubernetes. Amazon EKS, un servicio gestionado de Kubernetes, facilita la ejecución de clusters en AWS, administrando la disponibilidad y escalabilidad del plano de control de Kubernetes, y proporcionando soporte de escalado automático y gestión del ciclo de vida de los nodos de computación, ayudando a ejecutar aplicaciones contenedorizadas de alta disponibilidad. Amazon EKS es una plataforma ideal para ejecutar cargas de trabajo de entrenamiento distribuido debido a sus robustas integraciones con servicios de AWS y características de rendimiento. Se integra sin problemas con Amazon FSx for Lustre, un sistema de archivos de alto rendimiento, y con Amazon CloudWatch para monitoreo y logging, ofreciendo insights sobre el rendimiento del cluster y la utilización de recursos.
Para desplegar una solución robusta usando NVIDIA NeMo en un cluster de Amazon EKS, los pasos incluyen la configuración de un cluster EFA habilitado, la creación de un sistema de archivos FSx for Lustre, la preparación del entorno para NVIDIA NeMo y la modificación de manifiestos de Kubernetes para la preparación de datos y entrenamiento del modelo. Es esencial tener instancias reservadas con GPUs de alto rendimiento como las p4de.24xlarge o p5.48xlarge, que son populares para trabajos de entrenamiento de IA generativa distribuida.
En suma, este artículo destaca cómo se puede entrenar modelos de IA generativa a gran escala utilizando el NVIDIA NeMo Framework dentro de un cluster EKS, abordando los desafíos del entrenamiento de LLMs y aprovechando las herramientas y optimizaciones de NeMo para hacer el proceso más eficiente y rentable. Una guía detallada y scripts están disponibles en un repositorio de GitHub para facilitar la implementación de esta solución.







