Los modelos de lenguaje de gran tamaño (LLMs, por sus siglas en inglés) han revolucionado el procesamiento del lenguaje natural gracias a su habilidad para comprender y generar textos de manera similar al ser humano. Estos modelos, alimentados por vastos conjuntos de datos que cubren una amplia gama de temas y dominios, están siendo adaptados de forma cada vez más específica para optimizar su eficacia en aplicaciones particulares mediante técnicas de ajuste fino y aprendizaje con pocos ejemplos. Sin embargo, el alto requerimiento computacional de estos modelos presenta desafíos significativos para alcanzar tiempos de respuesta rápidos en contextos que requieren inmediatez, como la traducción en tiempo real o los asistentes de voz conversacionales.
En respuesta a esta necesidad, un grupo de investigadores ha desarrollado Medusa, un nuevo marco que promete acelerar el proceso de inferencia de los LLMs al añadir cabezas adicionales que permiten predecir múltiples tokens simultáneamente. En pruebas recientes utilizando Medusa-1, se logró duplicar la velocidad de inferencia sin comprometer la calidad del modelo. La aceleración varía según el tamaño del modelo y los datos utilizados, con un aumento registrado de 1.8 veces en ciertas pruebas.
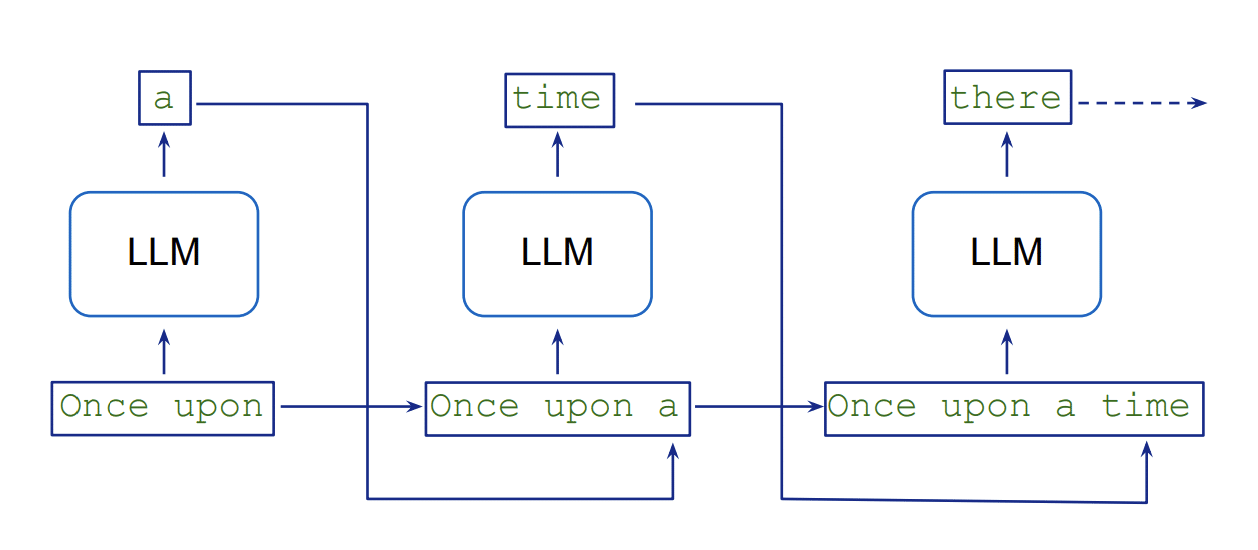
La generación de texto en los LLMs se lleva a cabo de forma secuencial, lo que introduce una latencia inherente debido a la dependencia de cada nuevo token de los anteriores. Este procedimiento requiere múltiples pasadas por el modelo, aumentando así el consumo de recursos. La técnica de «decodificación especulativa» intenta mitigar esta situación al usar un modelo más liviano para generar varias posibles continuaciones de texto en paralelo, que luego son verificadas por un modelo más preciso. En contraste, Medusa elimina la necesidad de un modelo previo mediante la incorporación de cabezas de decodificación que producen candidatos simultáneamente, reduciendo así el número de pasos secuenciales necesarios.
Este marco ha demostrado mejoras notables en términos de velocidad, alcanzando incrementos de hasta 2.8 veces en la inferencia dependiendo del tamaño y la complejidad del modelo. Actualmente, Medusa es compatible con modelos como Llama y Mistral, aunque su implementación podría requerir mayor capacidad de memoria, dependiendo de la cantidad de cabezas añadidas. Formar estas cabezas adicionales implica un gasto considerable en términos de tiempo y recursos, lo que debe ser tenido en cuenta en la planificación de proyectos. Otro aspecto a considerar es que el marco solo admite un tamaño de lote de uno, lo cual lo hace particularmente adecuado para aplicaciones que demandan baja latencia.
A través de un enfoque orientado y detallado, desde la preparación de los conjuntos de datos hasta su implementación en un endpoint de Amazon SageMaker AI, es posible acelerar la inferencia de LLMs en aplicaciones, logrando así tiempos de respuesta más rápidos y mejorando la experiencia del usuario. A medida que las empresas continúan explorando y ampliando el potencial de los LLMs, la optimización de su rendimiento mediante soluciones como Medusa se vuelve esencial para enfrentar los desafíos operativos y de calidad en la generación automatizada de textos.