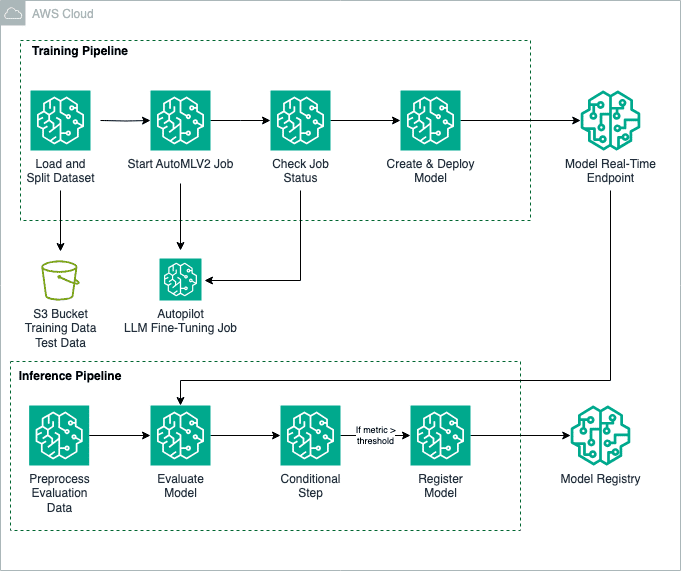
En el ámbito de la inteligencia artificial, el ajuste fino de modelos base se ha consolidado como un proceso esencial para mejorar la precisión y especificidad de las respuestas generadas por estos modelos en diversos dominios. Un reciente experimento ha puesto de relieve la efectividad de esta técnica utilizando Amazon SageMaker Autopilot y el SDK AutoMLV2, logrando afinar un modelo Meta Llama2-7B para tareas de respuesta a preguntas en exámenes de ciencias, abarcando disciplinas como física, química y biología.
El ajuste fino no se limita a estas tareas. También puede ser aplicado en diversas áreas, como la generación de resúmenes o la producción de textos en sectores como la atención médica, la educación y los servicios financieros. AutoMLV2, a través de Amazon SageMaker JumpStart, permite la instrucción y el ajuste fino de una variedad de modelos base. Además, Amazon SageMaker Pipelines simplifica el proceso mediante la automatización de las etapas del flujo de trabajo, abarcando desde la preparación de datos hasta la creación y afinamiento del modelo.
En esta metodología, el conjunto de datos SciQ, que cuenta con preguntas de examen en ciencias, se emplea para entrenar el modelo Llama2-7B. Los datos están preparados en archivos CSV, organizados en columnas que contienen entradas y salidas, donde las entradas representan los prompts y las salidas las respuestas correctas.
El ajuste fino se configura mediante parámetros específicos, como el nombre del modelo base, la aceptación de contratos de licencia del usuario final y los hiperparámetros que optimizan el aprendizaje del modelo, incluyendo el número de épocas y la tasa de aprendizaje. Estos ajustes permiten adaptar el entrenamiento del modelo a necesidades concretas.
Una vez completado el proceso de ajuste fino, el modelo se despliega en un punto de inferencia en tiempo real, facilitando así la obtención de resultados inmediatos. La evaluación de los modelos se lleva a cabo mediante la biblioteca fmeval, que proporciona una revisión exhaustiva con métricas personalizadas, asegurando un rendimiento adecuado en entornos reales.
Este enfoque no solo incrementa la precisión en las tareas asignadas al modelo, sino que también optimiza el proceso de implementación y evaluación, simplificando notablemente el despliegue de modelos en plataformas de producción. Además, establece un control de calidad, mediante la evaluación de métricas de rendimiento, garantizando que solo los modelos más fiables sean desplegados.
Este flujo automatizado es un paso significativo hacia la implementación eficaz de modelos de lenguaje de gran escala, permitiendo una integración más fluida en sistemas que requieren inferencias en tiempo real con alta precisión y relevancia. Este avance en la inteligencia artificial promete transformar el modo en que se integran y utilizan estos modelos en aplicaciones prácticas de diversos sectores.









