Los grandes modelos de lenguaje (LLMs, por sus siglas en inglés) poseen capacidades notables. No obstante, usarlos en aplicaciones orientadas al cliente a menudo requiere adaptar sus respuestas para alinearse con los valores e identidad de marca de una organización. En este artículo, demostramos cómo utilizar la optimización directa de preferencias (DPO), una técnica que permite ajustar un LLM con datos de preferencias humanas, junto con Amazon SageMaker Studio y Amazon SageMaker Ground Truth, para alinear las respuestas del modelo Meta Llama 3 8B Instruct con los valores de su organización.
Usando SageMaker Studio y SageMaker Ground Truth para DPO
Con DPO, se puede ajustar finamente un LLM con datos de preferencias humanas, como calificaciones o clasificaciones, para que genere respuestas que se alineen con las expectativas del usuario final. Esta técnica es computacionalmente eficiente y ayuda a mejorar la utilidad, honestidad e inofensividad del modelo, desviando al LLM de abordar ciertos temas y mitigando sesgos. Generalmente, se comienza seleccionando un modelo ya existente o entrenado anteriormente con ajuste fino supervisado (SFT, por sus siglas en inglés). Se usa el modelo para generar respuestas y se recopila retroalimentación humana sobre estas respuestas. Después, se utiliza esta retroalimentación para llevar a cabo el ajuste fino DPO y alinear el modelo con las preferencias humanas.
Al ajustar un LLM preentrenado con SFT o cargar un modelo ya afinado para DPO, normalmente se necesitan GPUs potentes. Lo mismo se aplica durante el ajuste fino DPO. Con Amazon SageMaker, se puede empezar rápidamente y experimentar de manera ágil utilizando notebooks gestionados de Jupyter equipados con instancias de GPU. Es posible iniciar rápidamente creando un espacio de JupyterLab en SageMaker Studio, el entorno de desarrollo integrado (IDE) diseñado específicamente para el aprendizaje automático (ML, por sus siglas en inglés), y lanzar una aplicación de JupyterLab que se ejecute en una instancia de GPU.
La orquestación del flujo de trabajo completo de recolección de datos y el desarrollo de una aplicación para que los anotadores califiquen o clasifiquen las respuestas del modelo para el ajuste fino DPO puede consumir mucho tiempo. SageMaker Ground Truth ofrece capacidades human-in-the-loop que ayudan a configurar flujos de trabajo, gestionar anotadores y recopilar retroalimentación de alta calidad y consistente.
Este artículo guía paso a paso sobre cómo usar DPO para alinear las respuestas de un modelo SFT finamente ajustado con los valores de un banco digital ficticio llamado Example Bank. El notebook se ejecuta en un espacio de JupyterLab en SageMaker Studio con una instancia ml.g5.48xlarge (8 GPUs A10G). Opcionalmente, se puede ejecutar este notebook dentro de una instancia de menor tamaño, como ml.g5.12xlarge (4 GPUs A10G) o ml.g6.12xlarge (4 GPUs L4) con cuantización de bitsandbytes. Se usa el modelo Meta Llama 3 8B Instruct, optimizado para casos de uso de diálogo del Hugging Face Hub, para generar respuestas, SageMaker Ground Truth para recopilar datos de preferencias y el DPOTrainer de la biblioteca HuggingFace TRL para el ajuste fino DPO junto con Parameter-Efficient Fine-Tuning (PEFT). Además, se despliega el modelo alineado en un endpoint de SageMaker para inferencia en tiempo real. Este enfoque se puede usar con otros modelos.
Resumen de la solución
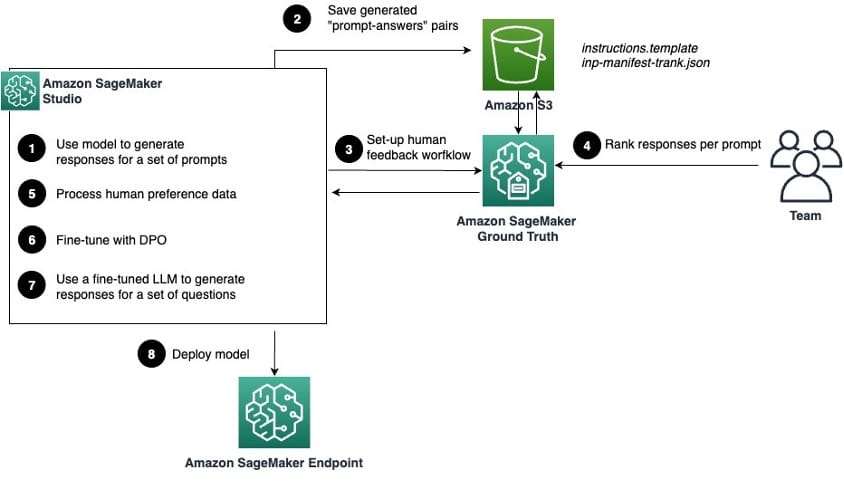
El diagrama siguiente ilustra el enfoque.
El flujo de trabajo contiene los siguientes pasos clave:
1. Cargar el modelo Meta Llama 3 8B Instruct en SageMaker Studio y generar respuestas para un conjunto curado de preguntas comunes y tóxicas. El conjunto de datos sirve como punto de referencia inicial para el rendimiento del modelo.
2. Las parejas de pregunta-respuesta generadas se almacenan en Amazon Simple Storage Service (S3). Estas se presentarán a los anotadores humanos más tarde para que puedan clasificar las respuestas del modelo.
3. Crear un flujo de trabajo en SageMaker Ground Truth para recopilar datos de preferencias humanas para las respuestas. Esto implica crear un equipo de trabajo, diseñar una interfaz de usuario para la recopilación de retroalimentación y configurar una tarea de etiquetado.
4. Los anotadores humanos interactúan con el portal de etiquetado para evaluar y clasificar las respuestas del modelo en función de su alineación con los valores de la organización.
5. Los datos recopilados se procesan para adherirse al formato esperado por el DPOTrainer.
6. Usando la biblioteca Hugging Face TRL y el DPOTrainer, se ajusta finamente el modelo Llama 3 con los datos procesados del paso anterior.
7. Poner a prueba el modelo ajustado en un conjunto de datos de evaluación para verificar su rendimiento y asegurarse de que cumple con los estándares deseados.
8. Cuando se esté satisfecho con el rendimiento del modelo, se puede desplegar en un endpoint de SageMaker para inferencia a escala en tiempo real.







