En un mundo inundado de contenido audiovisual, la capacidad de encontrar videos relevantes de manera eficiente se ha convertido en un reto crucial tanto para empresas como para usuarios particulares. La búsqueda semántica de videos surge como una herramienta revolucionaria que permite localizar contenidos específicos usando lenguaje natural, a través de consultas textuales o descripciones intuitivas.
Gracias al preentrenamiento avanzado de modelos de visión por computadora, se han ampliado las capacidades de estos sistemas para reconocer una amplia gama de conceptos visuales, sin necesidad de anotaciones manuales. Estos modelos, entrenados con enormes bases de datos, permiten ahora aplicar descripciones en lenguaje natural para identificar o describir visualmente nuevos conceptos, lo que tiene aplicaciones en tareas como la clasificación de imágenes y el análisis semántico.
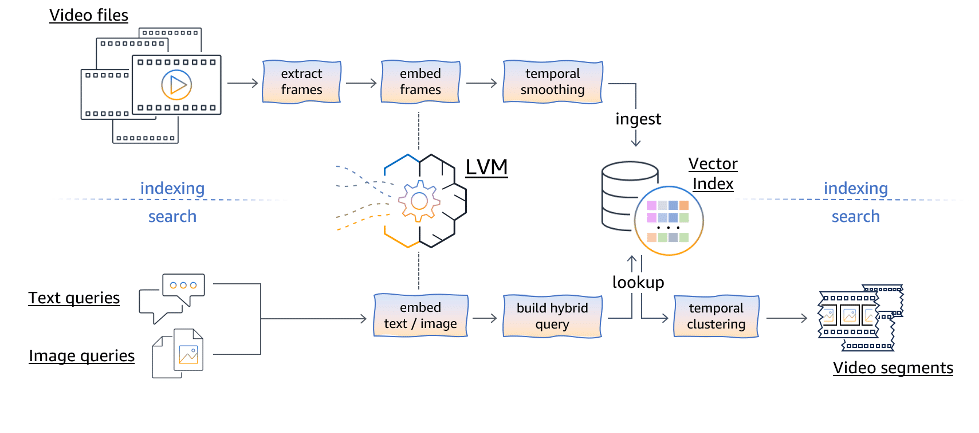
Recientes investigaciones han avanzado en el uso de modelos de visión a gran escala (LVMs) para la búsqueda semántica de videos. Utilizando Amazon SageMaker para el procesamiento de contenido y Amazon OpenSearch Serverless para realizar búsquedas con baja latencia, se han desarrollado métodos pioneros, como el suavizado temporal y el agrupamiento, que mejoran significativamente el rendimiento en la búsqueda de videos.
La implementación de este sistema se basa en integrar modalidades textuales y visuales mediante técnicas avanzadas de aprendizaje multimodal. Esto facilita la comprensión y el reconocimiento de diversos conceptos visuales extraídos de grandes bases de datos, permitiendo ejecutar múltiples tareas de visión por computadora sin ajustes personalizados.
El proceso se organiza en dos partes: un pipeline de indexación y la lógica de búsqueda de video en línea. El pipeline se encarga de procesar los archivos de video, extrayendo cuadros individuales y mapeándolos en representaciones vectoriales de alta dimensión. Esta técnica captura la información semántica del contenido visual de manera eficaz.
La búsqueda semántica se realiza a través de consultas textuales o visuales, embebidas en un espacio de representación multimodal. Esto no solo permite encontrar fotogramas relevantes según su coincidencia conceptual, sino que también organiza fotogramas consecutivos en segmentos coherentes a nivel semántico mediante técnicas de agrupamiento temporal.
Evaluaciones recientes del sistema han mostrado resultados prometedores, especialmente en la identificación de momentos clave en eventos deportivos y otras tareas específicas en videos extensos. La calidad y diversidad de las búsquedas destacan la eficacia del sistema, ofreciendo un equilibrio óptimo entre la recuperación precisa, la diversidad y la eficiencia computacional. Este avance promete transformar la manera en que gestionamos y descubrimos información en un océano creciente de contenido digital.









