La creciente demanda de aplicaciones impulsadas por inteligencia artificial (IA) ha llevado a muchas organizaciones a enfrentar retos significativos en términos de latencia y costo, especialmente al manejar modelos de lenguaje de gran tamaño (LLMs). Estos modelos, al procesar texto de manera secuencial y predecir un token a la vez, pueden generar retrasos que afectan negativamente la experiencia del usuario. Además, el alto volumen de llamadas a estos modelos puede exceder los límites presupuestarios y poner presión financiera a las organizaciones.
Para mitigar estos desafíos, se ha presentado una estrategia innovadora que busca optimizar las aplicaciones basadas en LLM mediante un esquema de almacenamiento en caché intermedio. Esta solución, que utiliza Amazon OpenSearch Serverless y Amazon Bedrock, ofrece a los desarrolladores la posibilidad de guardar y acceder a respuestas repetidas, mejorando la eficiencia y reduciendo los tiempos de respuesta. Amazon Bedrock, un servicio gestionado que proporciona modelos base de alto rendimiento, facilita la construcción de aplicaciones de IA generativa con un solo API, asegurando seguridad, privacidad y responsabilidad.
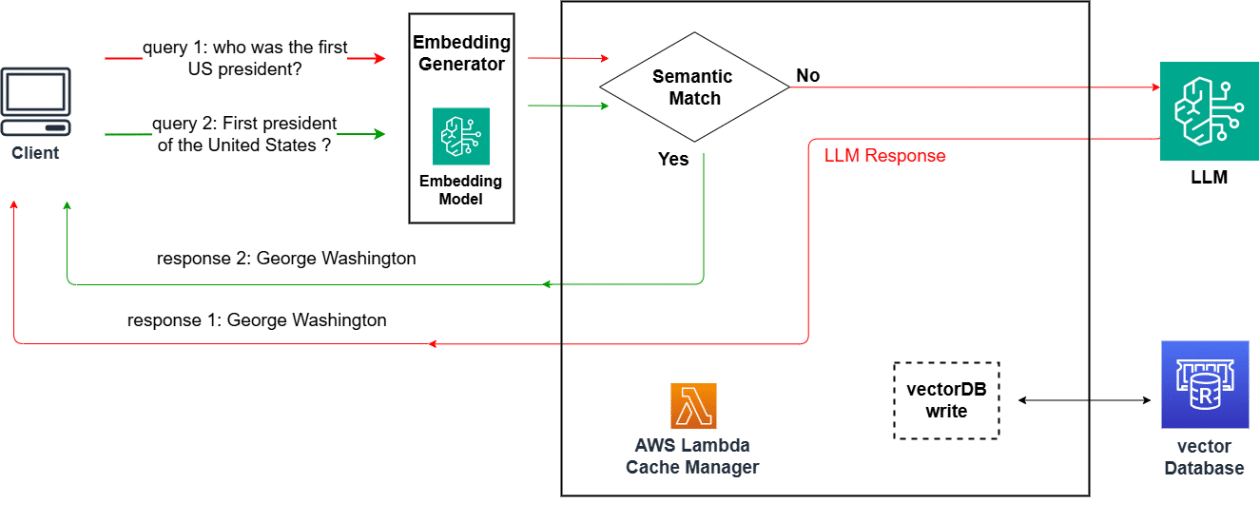
La esencia de esta nueva estrategia radica en el funcionamiento de la caché como un buffer que intercepta las solicitudes de lenguaje natural antes de alcanzar el modelo principal. Al almacenar consultas semánticamente similares, se permite una recuperación rápida de respuestas sin necesidad de hacer una nueva generación con el modelo LLM. Esto es clave para lograr un equilibrio entre aumentar los aciertos de la caché y minimizar las colisiones.
Un ejemplo práctico de la implementación de este sistema de caché se ve en los asistentes de IA para empresas de viajes, donde se pueden priorizar altos niveles de recuerdo al guardar más respuestas, incluso si ocasionalmente hay superposición de solicitudes. Por otro lado, un asistente para agentes de servicio requeriría asignaciones precisas de cada solicitud para minimizar los errores.
El sistema opera mediante el almacenamiento de consultas de texto en forma de incrustaciones vectoriales, transformándolas en vectores que luego se almacenan. Al utilizar modelos de incrustación gestionados por Amazon Bedrock, se pueden establecer bases de datos de vectores robustas con OpenSearch Serverless.
La implementación de esta solución no solo mejora los tiempos de respuesta, sino que también supone una considerable reducción de costos. En general, los modelos de incrustación resultan más económicos en comparación con los de generación, asegurando eficiencia en numerosos casos de uso. Esta innovación no solo mejora la eficiencia de los sistemas LLM, sino que también optimiza la experiencia del usuario al permitir ajustar los umbrales de similitud, equilibrando los aciertos y colisiones en la caché.









