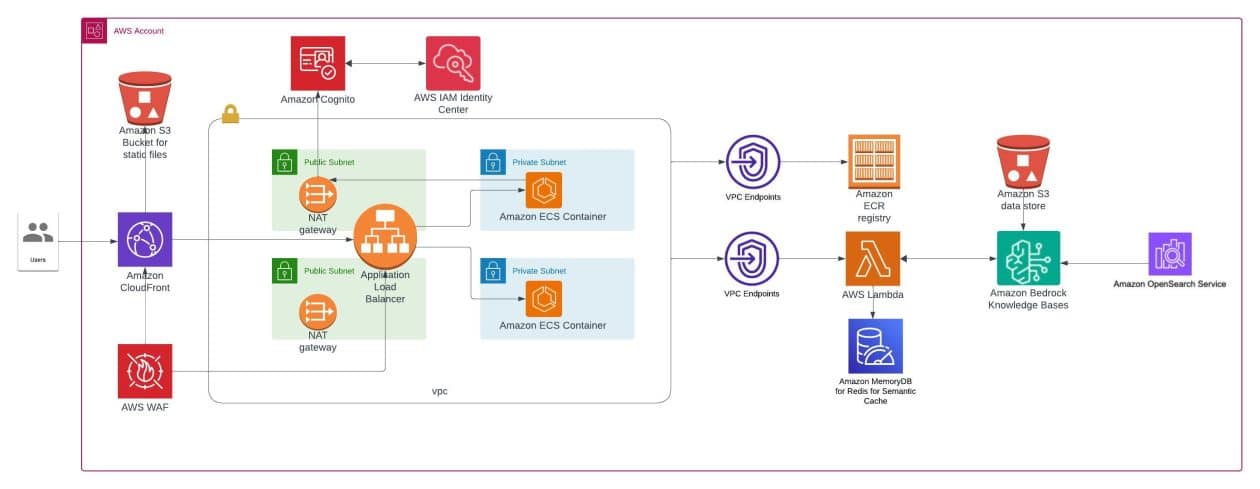
La inteligencia artificial generativa ha emergido como una fuerza transformadora, atrayendo la atención de diversas industrias gracias a su potencial para crear, innovar y resolver problemas complejos. Sin embargo, pasar de un concepto inicial a una aplicación lista para producción implica tanto desafíos como oportunidades. Este proceso requiere la creación de soluciones escalables, fiables e impactantes, capaces de generar valor empresarial y satisfacer a los usuarios.
Un desarrollo prometedor en este ámbito es la aparición de las aplicaciones de Generación Aumentada por Recuperación (RAG, por sus siglas en inglés). Este método optimiza la salida de un modelo base para que consulte una base de conocimientos externa antes de generar una respuesta.
El camino hacia la producción de una aplicación RAG, desde una fase de prueba o producto mínimo viable, exige técnicas de optimización que garanticen que las soluciones sean confiables, rentables y de alto rendimiento. Los ingenieros de machine learning deben equilibrar cuidadosamente la calidad, el costo y la latencia según las necesidades específicas de sus casos de uso y requisitos empresariales.
Un marco de evaluación efectivo es crucial para medir y optimizar los sistemas RAG a medida que avanzan desde un concepto inicial hacia una producción establecida. Este marco debe incluir métricas generales para una evaluación holística de toda la tubería RAG, así como métricas específicas para los componentes de recuperación y generación, permitiendo mejoras centradas en cada fase del sistema.
Para mejorar el rendimiento del recuperador, es esencial cómo se almacena la información en el vector store. También es importante considerar cómo se divide un documento en fragmentos, eligiendo estrategias de partición que mantengan las relaciones inherentes dentro del documento para una recuperación más efectiva.
La calidad del generador es asimismo vital. La redacción de una consulta efectiva puede influir significativamente en la precisión de la generación, así como el uso de técnicas de reranking que analicen la relevancia semántica entre la consulta y los documentos recuperados.
En el contexto de un proceso RAG, un equilibrio entre costo y latencia es fundamental. Estrategias de almacenamiento en caché y procesamiento por lotes pueden mejorar el rendimiento general y reducir el uso de recursos. También es crucial garantizar la privacidad y seguridad de los datos, implementando medidas de seguridad en cada capa de la aplicación.
Los aspectos de hosting y escalado también son relevantes. La elección de una solución adecuada para alojar la infraestructura, junto con herramientas de orquestación y pipelines de integración continua, facilitará la escalabilidad conforme crece la demanda. Es vital construir un sistema adaptado a los requisitos del flujo de trabajo de IA generativa y a las necesidades del frontend y backend.
Finalmente, implementar prácticas de IA responsable es esencial para asegurar un despliegue ético y seguro de estos sistemas. Esto incluye el filtrado de contenido perjudicial y la verificación de respuestas para minimizar errores. En su conjunto, al abordar estos aspectos, las organizaciones pueden transformar sus pruebas de concepto basadas en RAG en soluciones robustas y listas para la producción, capaces de ofrecer un alto rendimiento, rentabilidad y respuestas de baja latencia a sus usuarios.









