En los últimos meses, el desarrollo de modelos de lenguaje de gran escala ha impulsado la adopción de asistentes virtuales en diversas empresas. Estos sistemas buscan mejorar tanto la atención al cliente como la eficiencia de los equipos internos, implementando asistentes de chat basados en modelos que utilizan técnicas de recuperación aumentada por generación (RAG). Este enfoque permite a las organizaciones consultar documentos específicos de la empresa para responder eficientemente a preguntas relacionadas con casos de uso particulares.
Uno de los desarrollos más destacados ha sido la mejora en disponibilidad y capacidades de los modelos fundacionales multimodales. Estos modelos tienen la habilidad de interpretar y generar texto a partir de imágenes, conectando la información visual con el lenguaje natural. Sin embargo, su limitación radica en su dependencia de los datos contenidos en sus conjuntos de entrenamiento originales.
En este escenario, Amazon Web Services (AWS) ha mostrado cómo crear un asistente de chat multimodal utilizando los modelos de Amazon Bedrock. Este sistema innovador permite a los usuarios enviar imágenes y plantear preguntas para recibir respuestas basadas en documentos empresariales específicos. Un ejemplo del uso de este tipo de asistente se da en la industria minorista, donde podría optimizar la venta de productos, o en la fabricación de equipos, proporcionando soporte en el mantenimiento de maquinaria.
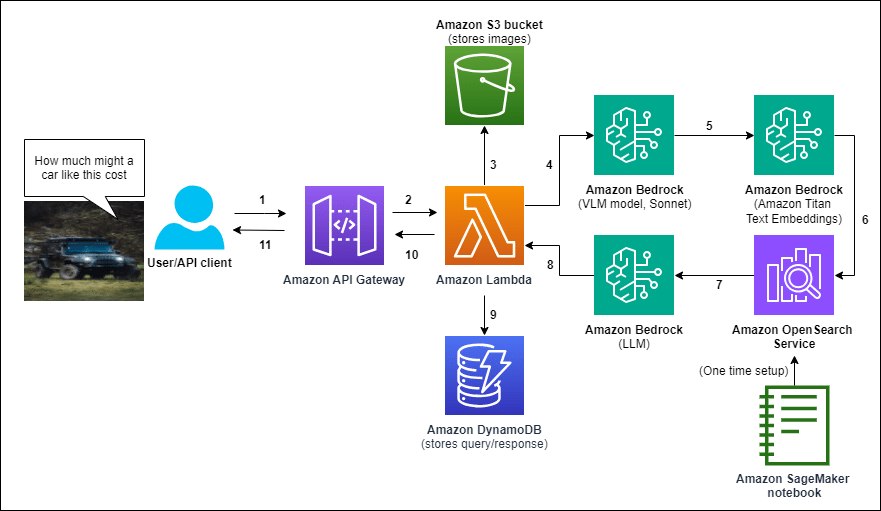
La solución de AWS inicia con la creación de una base de datos vectorial de documentos relevantes mediante Amazon OpenSearch Service, un poderoso y flexible motor de búsqueda. El siguiente paso es el despliegue del asistente de chat completo, utilizando una plantilla de AWS CloudFormation.
El proceso comienza con la subida de una imagen y la formulación de una pregunta por parte del usuario. Estas entradas son procesadas a través de Amazon API Gateway hacia una función de AWS Lambda, que actúa como núcleo de procesamiento. La imagen se almacena en Amazon S3, lo que permite análisis futuros del asistente. La función Lambda coordina múltiples llamados a los modelos de Amazon Bedrock para generar una descripción textual de la imagen, convertir tanto la pregunta como la descripción en representaciones vectoriales, recuperar datos relevantes de OpenSearch y generar una respuesta basada en los documentos obtenidos. Finalmente, tanto la consulta del usuario como la respuesta son almacenadas en Amazon DynamoDB, asociándolas al ID de la imagen en S3.
Este sistema presenta una oportunidad considerable para sectores que requieren respuestas específicas basadas en datos propios y entradas multimodales. Un caso de uso presentado en este contexto es el del mercado de automóviles, donde los usuarios pueden subir imágenes de vehículos y obtener respuestas fundamentadas en una base de datos de listados de autos, demostrando la aplicabilidad de la tecnología en diversos entornos.
La ventaja principal de este sistema radica en su capacidad para ofrecer respuestas precisas y contextuales basadas en datos específicos de una empresa, mejorando la experiencia del usuario y aumentando la eficiencia operativa. Además, la solución ofrece personalización y escalabilidad, permitiendo a las empresas adaptar el asistente a sus necesidades y explorar nuevos horizontes en la interacción humano-máquina.









