Implementar resiliencia en la infraestructura de entrenamiento de hardware es esencial para mitigar riesgos y permitir un entrenamiento de modelos sin interrupciones. Al incorporar funciones como monitoreo proactivo de salud y mecanismos de recuperación automática, las organizaciones pueden crear un entorno tolerante a fallos capaz de manejar fallos de hardware u otros problemas sin comprometer la integridad del proceso de entrenamiento.
Recientemente, se ha introducido el detector de problemas y recuperación de nodos AWS Neuron como DaemonSet para AWS Trainium y AWS Inferentia en Amazon Elastic Kubernetes Service (Amazon EKS). Este componente puede detectar rápidamente problemas raros cuando fallan los dispositivos Neuron, monitoreando los logs, y marca los nodos de trabajo con dispositivos Neuron defectuosos como no saludables, reemplazándolos con nuevos nodos de trabajo. Esto incrementa la confiabilidad del entrenamiento de ML y reduce el tiempo y los costos desperdiciados debido a fallos de hardware.
Esta solución es aplicable si se utilizan nodos gestionados o grupos de nodos autogestionados en Amazon EKS. Actualmente, la recuperación automática de nodos provisionados por Karpenter no es compatible.
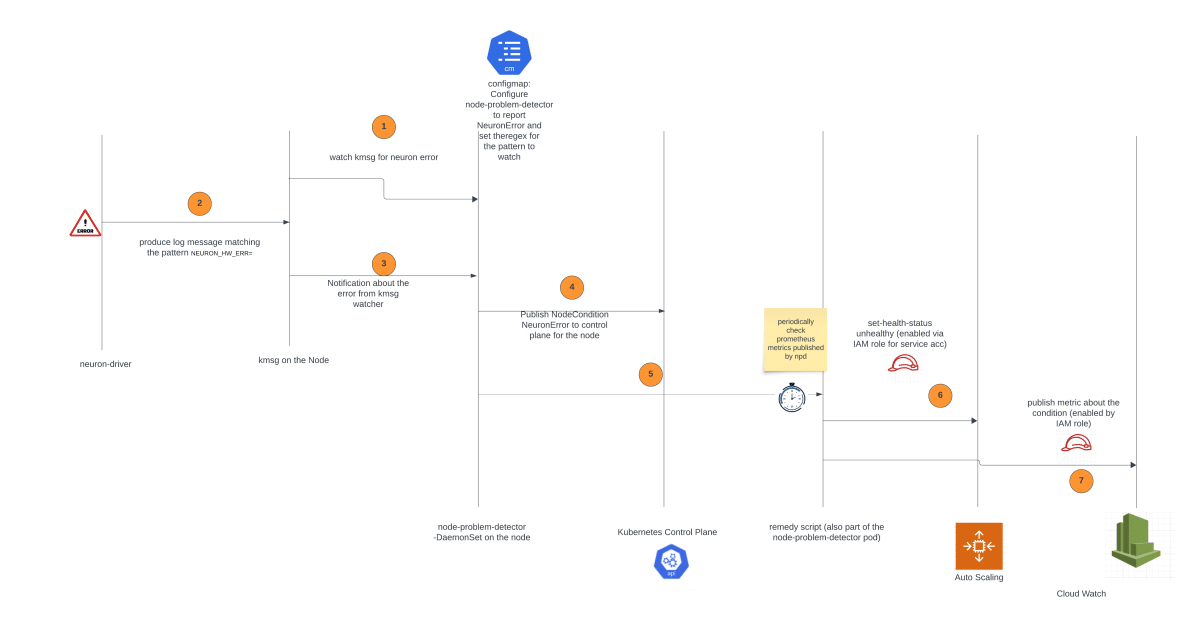
La solución se basa en el detector de problemas y recuperación de nodos DaemonSet, una herramienta diseñada para detectar y reportar automáticamente varios problemas a nivel de nodos en un clúster de Kubernetes. El detector de problemas de nodos monitoriza continuamente los logs del kernel (kmsg) en los nodos de trabajo. Si detecta mensajes de error relacionados específicamente con el dispositivo Neuron (Trainium o AWS Inferentia), cambiará el NodeCondition a NeuronHasError en el servidor API de Kubernetes. El agente de recuperación de nodos, que es un componente separado, verifica periódicamente las métricas de Prometheus expuestas por el detector de problemas de nodos. Si encuentra una condición indicativa de un problema con el dispositivo Neuron, tomará acciones automáticas, marcando la instancia afectada como no saludable y lanzando un reemplazo. Además, el agente de recuperación publicará métricas de Amazon CloudWatch para seguimiento y alerta.
El siguiente diagrama ilustra la arquitectura de la solución y el flujo de trabajo.
La solución implica crear un clúster EKS con nodos de trabajo Trn1, desplegar el complemento Neuron para el detector de problemas de nodos e inyectar un mensaje de error en el nodo. Se observa el nodo fallando siendo detenido y reemplazado por uno nuevo, y se encuentra una métrica en CloudWatch indicando el error.
Antes de comenzar, asegúrese de haber instalado las siguientes herramientas en su máquina:
Despliegue del complemento de detección y recuperación de problemas de nodos:
1. Cree un clúster EKS utilizando los datos de un módulo Terraform de EKS.
2. Instale la IAM role y el complemento del detector de problemas de nodos.
3. Cree una política actualizando los valores clave de Resource y ec2:ResourceTag/aws:autoscaling:groupName para que correspondan con su grupo de nodos y grupo de autoescalado respectivamente.
4. Instale el complemento de detección y recuperación de problemas de Neuron.
El detector de problemas de nodos no tomará ninguna acción por defecto en el nodo fallado. Si desea que la instancia EC2 sea terminada automáticamente por el agente, actualice el DaemonSet.
Prueba del detector y recuperación de problemas de nodos:
Simule un error de dispositivo inyectando logs de error en la instancia y alrededor de dos minutos después, el error será identificado. Amazon EKS acordonará el nodo y desalojará los pods en el nodo afectado. Puede verificar las métricas en la consola de CloudWatch.
En un escenario real, si está ejecutando un trabajo de entrenamiento distribuido y hay un error irreparable en un nodo, el detector de problemas lo eliminará proactivamente del clúster y el entrenamiento se reanudará desde el punto de control anterior.
Para acciones personalizadas adicionales, puede crear alarmas de CloudWatch observando las métricas de error y utilizar consultas CloudWatch Metrics Insights para evaluar las alarmas.
Limpieza:
Para limpiar todos los recursos aprovisionados, ejecute el script de limpieza proporcionado.
En conclusión, el detector de problemas y recuperación de Neuron para Amazon EKS mejora la confiabilidad y tolerancia a fallos de sus cargas de trabajo de entrenamiento de machine learning en caso de fallos de nodos al ejecutar instancias EC2 basadas en Neuron.









