En el mundo del aprendizaje automático, la eficiencia y automatización se han convertido en componentes clave para el éxito. Amazon ha dado un paso significativo en esta dirección con su herramienta SageMaker Pipelines, diseñada para facilitar la vida de científicos de datos y desarrolladores al simplificar los flujos de trabajo de aprendizaje automático (ML). Esta plataforma no solo automatiza la gestión de infraestructuras, sino que también optimiza cada paso del proceso de desarrollo de modelos, desde la preparación de los datos hasta el despliegue final.
Con la ayuda de un sencillo SDK de Python, el usuario puede orquestar flujos de trabajo complejos y visualizarlos con facilidad en el entorno de SageMaker Studio. Este enfoque minimiza la carga en tareas rutinarias, como la ingeniería de características y la preparación de datos, permitiendo que los equipos se enfoquen en la innovadora tarea de modelar. Además, SageMaker Pipelines se integra perfectamente con Automatic Model Tuning de Amazon para ajustar automáticamente los valores de hiperparámetros, mejorando el rendimiento del modelo según las métricas del usuario.
Un área en auge dentro de la comunidad de ML son los modelos de conjuntos, los cuales mejoran la precisión obtenida al combinar múltiples modelos. SageMaker Pipelines permite a los desarrolladores implementar estos procesos de forma rápida, logrando eficiencia y precisión en los resultados. Un caso de uso reciente ilustra esta capacidad: un modelo de conjunto fue entrenado y desplegado para ayudar a los representantes de ventas de Salesforce a generar nuevos clientes e identificar oportunidades. Este modelo aplicó aprendizaje no supervisado para detectar distintos casos de uso, esenciales para diferentes industrias y distribuciones de ingresos.
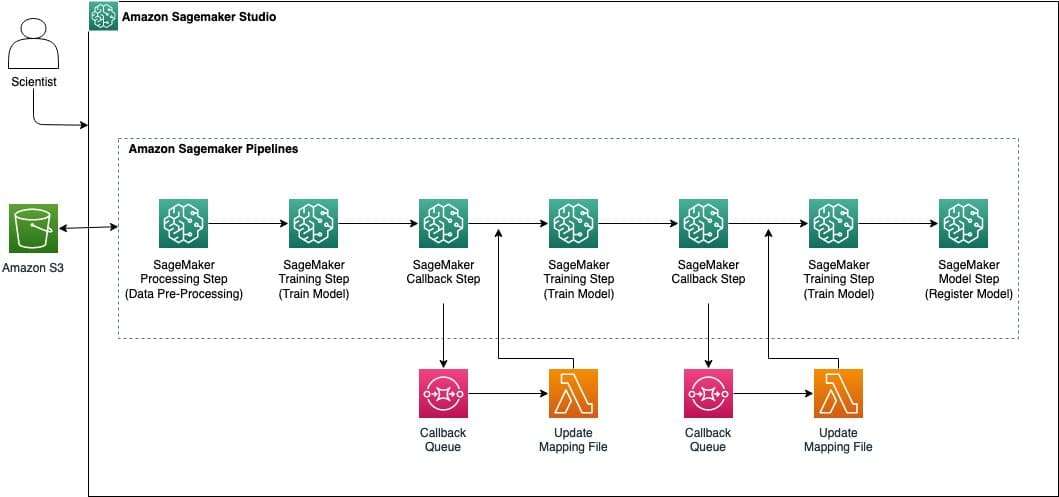
La solución utiliza un enfoque de modelos secuenciales con BERTopic, superando así las limitaciones de modelos previos como LSA y LDA. Tres modelos BERTopic organizados jerárquicamente se aplicaron para lograr una agrupación eficaz, apoyados por técnicas avanzadas como UMAP para reducción de dimensiones y BIRCH para clustering.
A pesar de los desafíos, como la necesidad de preprocesar grandes volúmenes de datos y la infraestructura escalable para gestionar millones de registros, la flexibilidad de los pipelines es un factor crítico para su éxito. SageMaker Studio se presenta como una plataforma colaborativa y eficiente donde se orquesta el flujo de trabajo ML a gran escala, a través de un proceso minucioso de pasos de procesamiento, entrenamiento y modelado.
Este caso subraya la capacidad de Amazon SageMaker Pipelines para enfrentar los desafíos de automatización y escalabilidad, mostrando su potencial para transformar las estrategias de AI/ML en organizaciones de todo el mundo.









