Los equipos de ciencia de datos se encuentran con múltiples obstáculos al intentar llevar sus modelos desde un ambiente de desarrollo hasta el de producción. Estos desafíos incluyen la dificultad para integrar los modelos desarrollados con el entorno de producción del equipo de TI, la necesidad de ajustar el código de ciencia de datos a los estándares de seguridad y gobernanza de la empresa, asegurar el acceso a datos de calidad de producción y mantener la repetibilidad y reproducibilidad de las tuberías de aprendizaje automático. La falta de una infraestructura adecuada y de plantillas estandarizadas complica aún más el proceso.
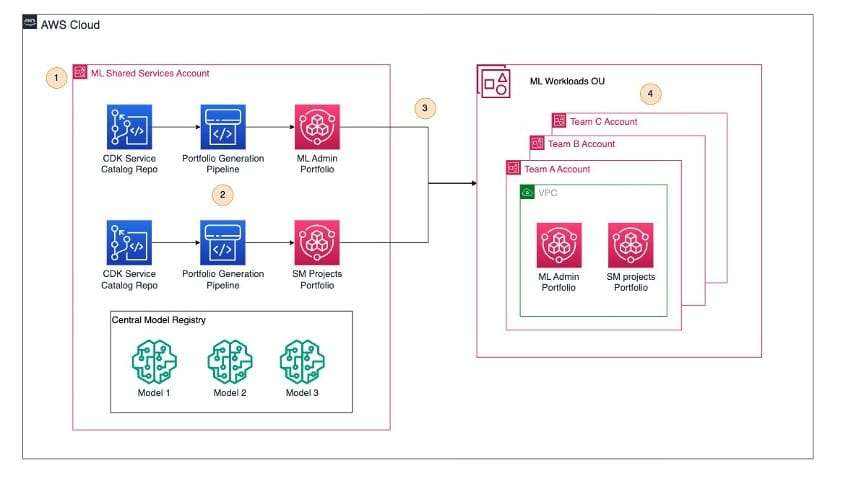
Para afrontar estos desafíos, ha surgido una nueva plataforma que permite a los equipos de aprendizaje automático gestionar por sí mismos su entorno de manera segura. Esta herramienta facilita el desarrollo de modelos a través de plantillas predefinidas, establece un registro centralizado de modelos para fomentar la colaboración y reutilización, y estandariza los procesos de aprobación y despliegue de modelos.
En este proceso intervienen varios roles clave. El líder del equipo de ciencia de datos se encarga de gestionar las cuentas de los equipos de desarrollo, regular el acceso, y promover procesos estandarizados de desarrollo y aprobación. Los científicos de datos se dedican al análisis, desarrollo y evaluación de modelos, registrando sus resultados en un registro especializado. Los ingenieros de aprendizaje automático desarrollan y controlan los procesos de despliegue de modelos, mientras que un oficial de gobernanza evalúa el rendimiento de estos antes de autorizar su implementación. Por último, los ingenieros de plataforma son responsables de establecer procesos estandarizados y gestionar la infraestructura necesaria para compartir artefactos de modelos.
Los beneficios de esta plataforma son significativos. En primer lugar, asegura que cada etapa del ciclo de vida del aprendizaje automático cumpla con los estándares de seguridad y gobernanza de la organización, reduciendo de este modo los riesgos. Asimismo, los equipos de ciencia de datos adquieren la autonomía necesaria para crear cuentas y acceder a los recursos necesarios, minimizando así las restricciones de recursos que a menudo dificulta su labor.
Además, la automatización de muchos de los pasos manuales rutinarios permite a los científicos de datos concentrar su esfuerzo en construir modelos y extraer conocimientos valiosos de los datos, en lugar de gestionar la infraestructura subyacente. El registro centralizado de modelos mejora la colaboración entre equipos y aumenta la visibilidad sobre el trabajo desarrollado, reduciendo la duplicidad de esfuerzos.
El proceso estandarizado para la revisión y uso de modelos promueve una colaboración estrecha entre las áreas de ciencia de datos y negocios, permitiendo que los modelos sean evaluados, aprobados y desplegados rápidamente en producción. Esto es crucial para aportar valor de manera eficaz a la organización.
Este enfoque integral para la gestión del ciclo de vida del aprendizaje automático a gran escala ofrece beneficios significativos en términos de seguridad, agilidad, eficiencia y alineación entre funciones. La plataforma, diseñada con una arquitectura de múltiples cuentas, habilita la colaboración efectiva entre diferentes roles para escalar las operaciones de aprendizaje automático, contribuyendo así a una implementación más eficaz y adaptable de soluciones de ciencia de datos en el ámbito empresarial.