En la actualidad, las empresas enfrentan el desafío de procesar miles de documentos diarios que contienen información crítica para sus operaciones. Desde facturas y contratos hasta órdenes de compra, la localización y extracción precisa de datos específicos ha sido una tarea compleja, que requiere el uso de soluciones avanzadas de visión por computadora.
El desarrollo de tecnologías ha demostrado la dificultad de este reto. Inicialmente, los enfoques como YOLO (You Only Look Once) revolucionaron la detección de objetos al permitir su identificación en tiempo real, mientras que métodos como RetinaNet y DETR introdujeron mejoras significativas mediante técnicas como Focal Loss y arquitecturas basadas en transformadores. No obstante, estas soluciones aún dependían de grandes volúmenes de datos de entrenamiento y modelos complejos.
Sin embargo, la aparición de modelos de lenguaje grandes multimodales (LLMs) representa un cambio significativo. Combinando capacidades avanzadas de visión y procesamiento de lenguaje natural, estos modelos ofrecen ventajas notables. Características como la reducción de arquitecturas especializadas y la capacidad de operar sin aprendizaje supervisado destacan entre sus beneficios, además de interfaces de lenguaje natural que especifican tareas y ofrecen adaptación flexible a diversos documentos.
Un ejemplo de este avance es el uso de modelos en Amazon Bedrock, particularmente Amazon Nova Pro, para localizar con alta precisión campos dentro de documentos, simplificando la implementación y reduciendo errores manuales. La capacidad de estos modelos para comprender tanto el diseño visual como el significado semántico de los documentos mejora la eficiencia de operaciones empresariales, facilitando tareas como chequeos automáticos de calidad y protección de datos sensibles.
Tradicionalmente, localizar información en documentos dependía de sistemas basados en reglas y modelos especializados, que exigían mantener extensos conjuntos de datos de entrenamiento. En contraste, los LLMs ofrecidos en Amazon Bedrock transforman este paradigma, permitiendo una implementación más sencilla y robusta.
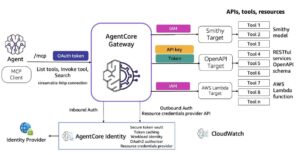
El sistema desarrollado procesa imágenes de documentos junto a textos solicitados, utilizando modelos integrados en Amazon Bedrock que devuelven las ubicaciones de los campos en coordenadas absolutas o normalizadas. Dos estrategias de solicitud —basadas en dimensiones de imagen y coordenadas escaladas— otorgan mayor flexibilidad al sistema.
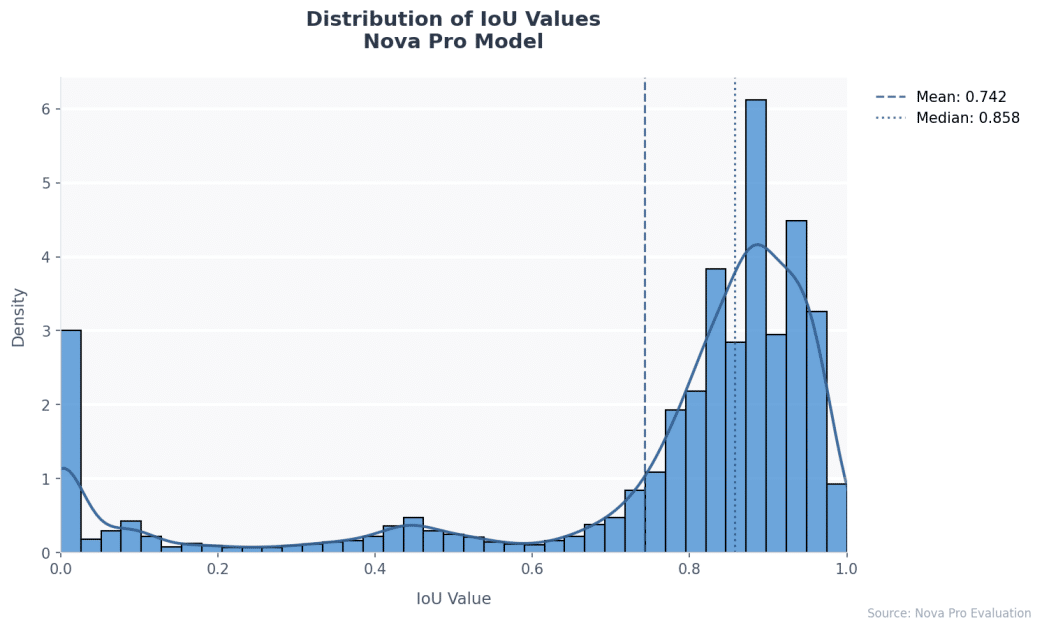
Un estudio de benchmarking con el dataset FATURA, compuesto por 10,000 facturas, mostró que los modelos pueden localizar y extraer campos con un mínimo esfuerzo de configuración, simplificando los flujos tradicionales de visión por computadora. En particular, Amazon Nova Pro ha sobresalido en el procesamiento documental empresarial, logrando una media de precisión del 0.8305, con un rendimiento constante en diferentes tipos de documentos.
Este avance no solo optimiza los flujos de trabajo, sino que también invita a las empresas a implementar soluciones innovadoras en su gestión documental.