Los modelos de lenguaje grandes (LLMs) están revolucionando el campo de la traducción automática, mostrando habilidades impresionantes que los posicionan como competidores fuertes frente a sistemas como Amazon Translate. Destacando por su capacidad para entender el contexto y los matices culturales del texto de entrada, estos modelos son capaces de ofrecer traducciones más naturales y precisas.
La importancia de esta capacidad se evidencia en la traducción de preguntas contextuales. Un ejemplo de esto es la frase «¿Te desempeñaste bien?», que puede tener variaciones significativas en su traducción dependiendo del contexto, como el deportivo. En estos casos, es crucial que los modelos de inteligencia artificial no solo comprendan el contexto, sino que también integren las particularidades culturales para proporcionar traducciones fluidas y exactas.
Empresas alrededor del mundo buscan aprovechar el potencial de los LLMs para optimizar la calidad de su contenido traducido mediante la localización, un proceso que combina la Traducción Automática con Edición Posterior (MTPE). Esta metodología no solo ofrece beneficios económicos al reducir costos, sino que también mejora la experiencia del usuario al ofrecer traducciones más rápidas y con un menor margen de error.
No obstante, los LLMs enfrentan desafíos significativos en el ámbito de la traducción automática. Dificultades como la calidad inconsistente en ciertos pares de idiomas, la falta de un patrón estándar para integrar conocimientos previos de traducciones (memoria de traducción o TM) y el riesgo de producir resultados erróneos o «alucinaciones» deben ser abordados. Sin embargo, a pesar de estos inconvenientes, el uso de LLMs sigue considerándose prometedor en la industria.
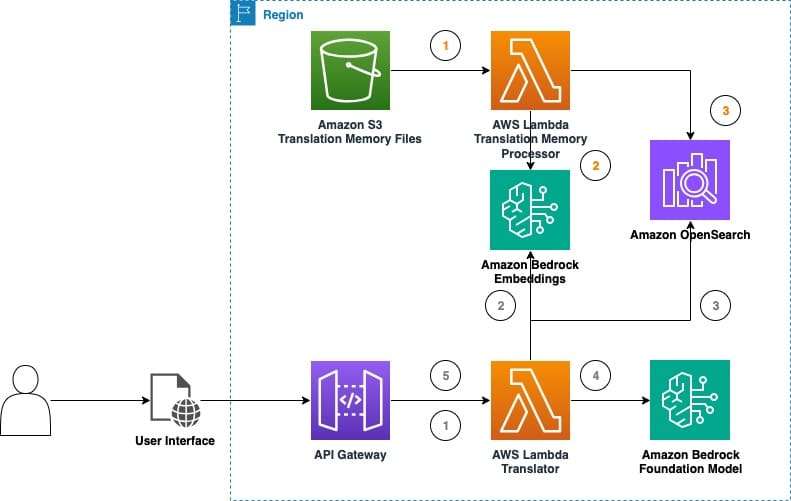
Para evaluar su eficacia en tiempo real, se ha implementado una solución que utiliza datos de Amazon Bedrock con el fin de recabar más información sobre el valor que los LLMs pueden aportar a la traducción de contenido. Al integrar técnicas de memoria de traducción, estas soluciones refuerzan la eficiencia y precisión, permitiendo una adaptación mejor a los términos específicos de cada dominio y estilo de contenido.
La unión de TMs y LLMs no solo mejora la calidad de las traducciones, sino que también facilita la reducción del esfuerzo de edición posterior, aumentando la productividad y reduciendo costos. Este proceso puede realizarse sin complicaciones mayores, utilizando las capacidades contextuales de los LLMs y las técnicas de ingeniería de prompts.
El denominado «parque de pruebas de traducción LLM» se configura como una aplicación práctica para experimentar con estas capacidades y evaluar distintas configuraciones de inferencia. En pruebas preliminares, los LLMs han demostrado adaptarse eficazmente al contexto de las frases, mejorando significativamente la calidad de las traducciones y la experiencia del usuario.
La continua exploración y desarrollo de LLMs en el ámbito de la traducción automática promete un futuro en el que la calidad de las traducciones sea superior, y en el que el proceso de localización sea más eficiente y accesible, beneficiando a empresas de diferentes tamaños.









