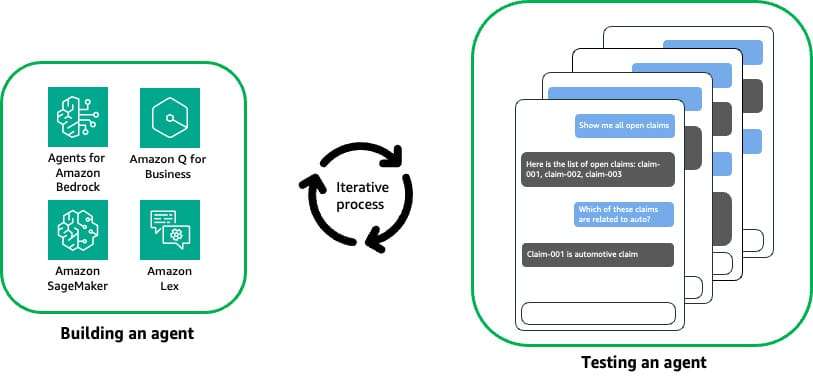
A medida que los agentes de inteligencia artificial conversacional ganan terreno en diversas industrias, la fiabilidad y consistencia son cruciales para proporcionar experiencias de usuario fluidas y confiables. Sin embargo, la naturaleza dinámica y conversacional de estas interacciones hace que los métodos tradicionales de prueba y evaluación sean desafiantes. Los agentes de IA conversacional abarcan múltiples capas, desde la Recuperación Aumentada de Generación (RAG) hasta mecanismos de llamadas a funciones que interactúan con fuentes de conocimiento externas y herramientas. Aunque los benchmarks existentes como MT-bench evalúan las capacidades del modelo, carecen de la capacidad de validar las capas de aplicación.
Los puntos de dolor comunes en el desarrollo de agentes de IA conversacional incluyen:
1. Probar un agente es a menudo tedioso y repetitivo, requiriendo a un humano para validar el significado semántico de las respuestas del agente.
2. Configurar casos de prueba adecuados y automatizar el proceso de evaluación puede ser difícil debido a la naturaleza conversacional y dinámica de las interacciones del agente.
3. Depurar y rastrear cómo los agentes de IA conversacional dirigen a la acción apropiada o recuperan los resultados deseados puede ser complejo, especialmente cuando se integran con fuentes de conocimiento externas y herramientas.
Para abordar estos desafíos, Agent Evaluation, una solución de código abierto que utiliza LLMs en Amazon Bedrock, permite la evaluación y validación integral de agentes de IA conversacional a escala.
Amazon Bedrock es un servicio completamente gestionado que ofrece una selección de modelos de altas prestaciones de compañías líderes en IA a través de una API única, junto con capacidades amplias para construir aplicaciones de IA generativa con seguridad, privacidad y IA responsable.
Agent Evaluation ofrece soporte integrado para servicios populares, orquestación de conversaciones concurrentes y multi-turnos con el agente durante la evaluación de sus respuestas, hooks configurables para validar acciones desencadenadas por el agente, integración en pipelines de CI/CD para automatizar la prueba de agentes y resúmenes de prueba generados para obtener información sobre el rendimiento, incluyendo historial de conversaciones, tasa de éxito de las pruebas y razonamiento para los resultados.
Usando Agent Evaluation, se puede acelerar el desarrollo y la implementación de agentes de IA conversacional a escala. Por ejemplo, en el caso de un agente para procesar reclamos de seguros, se busca probar la capacidad del agente de buscar y recuperar información relevante de reclamos existentes. Se comienzan las pruebas en la cuenta de desarrollo interactuando manualmente con el agente y luego se puede automatizar usando Agent Evaluation.
El flujo de trabajo típico incluye la configuración de un plan de prueba, la ejecución del plan desde la línea de comandos y la visualización de resultados. Si hay fallos, se depuran utilizando archivos de trazas detallados.
Además, Agent Evaluation se puede integrar con pipelines de CI/CD, permitiendo que cada cambio de código o actualización pase por una evaluación exhaustiva antes del despliegue. Esto ayuda a minimizar el riesgo de introducir errores o inconsistencias que puedan comprometer el rendimiento del agente y la experiencia del usuario.
Las consideraciones adicionales incluyen no utilizar el mismo modelo para evaluar que para alimentar al agente, implementar puertas de calidad estrictas para evitar despliegues de agentes que no cumplan con los umbrales esperados, y expandir y refinar continuamente los planes de prueba para cubrir nuevos escenarios y casos extremos.
Agent Evaluation representa un nivel avanzado de confianza en el desempeño de los agentes de IA conversacional, optimizando los flujos de trabajo de desarrollo, acelerando el tiempo de comercialización y proporcionando experiencias de usuario excepcionales.









