En un mundo cada vez más dependiente de los datos para el desarrollo de aplicaciones tecnológicas, la demanda de información precisa y confiable ha alcanzado niveles sin precedentes. En respuesta a este desafío, los modelos de inteligencia artificial generativa, en particular los grandes modelos de lenguaje (LLMs), están emergiendo como soluciones innovadoras. Estos avanzados modelos, entrenados con enormes conjuntos de datos, tienen la capacidad de crear contenido nuevo que abarca diversos formatos, como texto, audio y video, aplicados a distintos dominios empresariales.
El sector financiero ha sido uno de los beneficiarios más destacados de esta tecnología. Instituciones como el ficticio Banco ABC están adoptando modelos de aprendizaje automático (ML) para evaluar el riesgo de contraparte en transacciones de derivados extrabursátiles (OTC), que son complejos contratos financieros personalizados, incluyendo instrumentos como swaps y opciones. La gestión del riesgo de contraparte es crucial, ya que implica compartir riesgos y responsabilidades financieras entre las partes involucradas.
No obstante, desarrollar modelos precisos para evaluar el riesgo conlleva múltiples desafíos. A pesar de contar con grandes volúmenes de datos, estos pueden presentar sesgos o carecer de diversidad adecuada, comprometiendo la eficacia del modelo. Para abordar estos problemas, se propone el uso de la inteligencia artificial generativa mediante la técnica de Generación Aumentada por Recuperación (RAG), que mejora los LLMs incluyendo información adicional de fuentes externas que no se encontraba disponible durante el entrenamiento original.
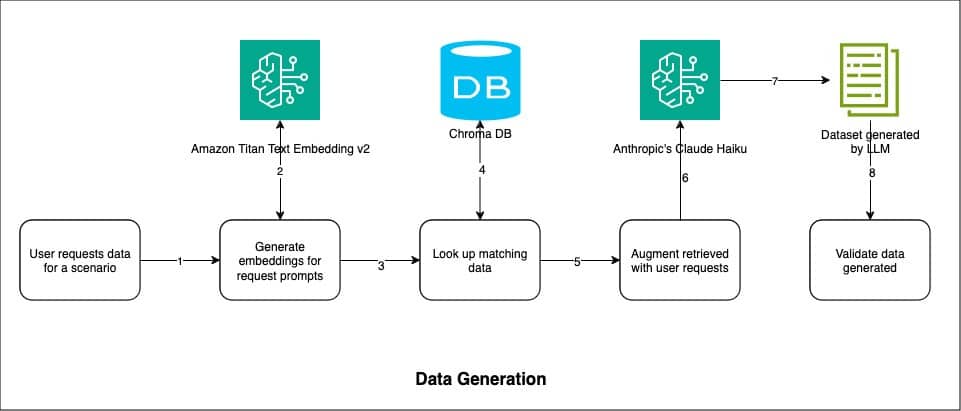
La implementación de este enfoque se divide en tres fases: indexación de datos, generación de datos y validación. En primer lugar, los datos de riesgo de contraparte son procesados y almacenados en una base de datos vectorial, facilitando búsquedas de similitud eficientes. Durante la generación de datos, se busca información coincidente en la base de datos que se alimenta a un modelo, como Claude Haiku de Anthropic, destacado por su capacidad de procesamiento rápido y generación de datos de alta calidad.
Es esencial validar los datos sintéticos generados para garantizar su calidad y fiabilidad. Se emplean herramientas estadísticas, como gráficos de cuantiles (Q-Q) y mapas de calor de correlación, para asegurar que los datos generados mantengan propiedades similares a los reales, evitando patrones artificiales o sesgos que podrían influir en decisiones empresariales.
Además, es crucial que las instituciones financieras se adhieran a prácticas responsables en el uso de inteligencia artificial, protegiendo la privacidad de los datos y asegurando que no se utilice información personal sin autorización. La combinación de innovación tecnológica y consideraciones éticas permitirá que las organizaciones aprovechen las ventajas de la inteligencia artificial, manteniendo al mismo tiempo la confianza de sus clientes.
En resumen, la generación de datos sintéticos mediante modelos generativos proporciona una solución eficaz para crear conjuntos de datos en el sector financiero. Este enfoque no solo permite que instituciones como el Banco ABC mejoren la evaluación del riesgo de contraparte, sino que también facilita decisiones más informadas y seguras en las transacciones OTC.









