Los asistentes conversacionales basados en la Generación Aumentada por Recuperación (RAG) están transformando el soporte al cliente, los servicios de ayuda internos y las herramientas de búsqueda empresarial. Esta innovadora tecnología se destaca por proporcionar respuestas rápidas y precisas utilizando los datos de la propia empresa, lo que mejora significativamente la experiencia del usuario. RAG permite emplear un modelo básico ya desarrollado, enriquecido con datos específicos, sin requerir complicados ajustes o reentrenamientos.
El Amazon Elastic Kubernetes Service (EKS) se presenta como una herramienta óptima para operar estos asistentes, ofreciendo flexibilidad y control total sobre los datos y la infraestructura. EKS se adapta de manera eficiente a diferentes cargas de trabajo, resultando en una opción rentable para demandas tanto constantes como fluctuantes. Además, su compatibilidad con aplicaciones existentes en entornos Kubernetes, ya sean locales o en la nube, facilita su integración en diversas plataformas tecnológicas.
En este contexto, los microservicios NVIDIA NIM revolucionan el despliegue de modelos de inteligencia artificial al integrarse con servicios de AWS como Amazon EC2, EKS y SageMaker. Estos microservicios, que se distribuyen usando contenedores Docker, simplifican la gestión de modelos de IA al automatizar configuraciones técnicas que requerirían tiempo y experiencia especializada.
El rol del operador NVIDIA NIM es esencial al facilitar la gestión y operación de diversos modelos en Kubernetes, contribuyendo a la reducción de la latencia de inferencia y mejorando las capacidades de escalabilidad automática, lo que resulta crucial para el manejo eficiente de recursos.
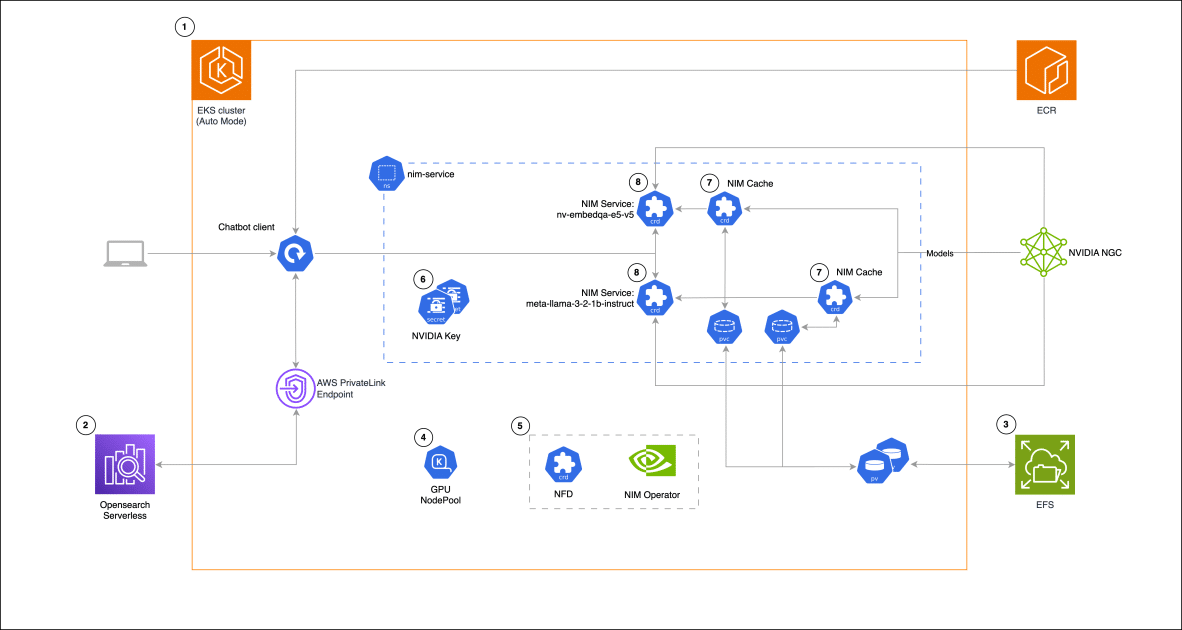
En una aplicación práctica, un asistente conversacional RAG se desarrolla utilizando NVIDIA NIM para manejar la inferencia de modelos de lenguaje, complementado con Amazon OpenSearch Serverless para gestionar vectores de alta dimensión. Esta infraestructura, apoyada en Kubernetes y EKS, optimiza el despliegue de cargas de trabajo heterogéneas de computación.
El proceso para implementar esta solución incluye desde la configuración del clúster EKS y OpenSearch Serverless, hasta la implementación de un sistema de archivos EFS y la creación de grupos de nodos GPU con Karpenter. Cada paso está diseñado para maximizar el rendimiento y la eficiencia de costes, integrando herramientas que facilitan la gestión de modelos y garantizan respuestas rápidas y precisas.
Finalmente, la implantación de un cliente para asistentes de chat utiliza bibliotecas como Gradio y LangChain, ofreciendo una interfaz intuitiva. Este sistema permite al asistente recuperar información relevante y generar respuestas contextuales, evidenciando cómo Amazon EKS es una solución efectiva para desplegar aplicaciones de inteligencia artificial, asegurando la confiabilidad y escalabilidad necesarias para enfrentar los desafíos del entorno empresarial contemporáneo.