La evaluación de los modelos de lenguaje de gran tamaño (LLM) se ha convertido en un componente esencial para las organizaciones que buscan maximizar el potencial de esta tecnología en constante evolución. Un marco innovador, denominado «LLM-as-a-judge», ha sido introducido, prometiendo simplificar y optimizar este proceso vital. Esta metodología dota a las empresas de la capacidad de evaluar la eficacia de sus modelos de inteligencia artificial mediante métricas predefinidas, asegurando así que la tecnología se alinea con sus metas y requisitos específicos. La adopción de este enfoque permite una medición precisa del rendimiento de los sistemas de IA, facultando a las compañías para tomar decisiones fundamentadas sobre selección, optimización y despliegue de modelos. Este enfoque no solo se anticipa a mejorar la fiabilidad y eficiencia de las aplicaciones de IA, sino que también promueve una adopción tecnológica más estratégica.
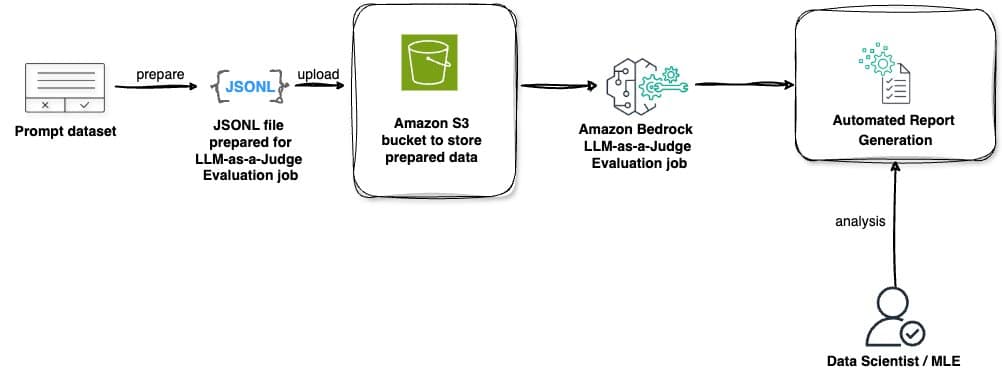
Amazon Bedrock es una de las plataformas que ha integrado estas capacidades avanzadas. Siendo un servicio totalmente gestionado, ofrece modelos fundacionales de alto rendimiento de destacadas empresas de IA a través de una única API. En los últimos desarrollos, Amazon Bedrock ha desvelado dos capacidades significativas de evaluación: el uso de «LLM-as-a-judge» como parte de su Evaluación de Modelos y la evaluación RAG para sus Bases de Conocimiento. Ambas funcionalidades incorporan la técnica «LLM-as-a-judge», aunque con diferentes enfoques evaluativos. Este marco asegura una guía detallada sobre la configuración de características, el inicio de evaluaciones mediante la consola y APIs de Python, y evidencia cómo esta innovadora característica de evaluación puede perfeccionar las aplicaciones de IA generativa a través de múltiples métricas tales como calidad, experiencia del usuario, cumplimiento de instrucciones y seguridad.
El método «LLM-as-a-judge» sobresale por una serie de características distintivas que lo apartan de los métodos de evaluación tradicionales. Entre sus ventajas se encuentra la evaluación inteligente automatizada, permitiendo que los modelos previamente entrenados realicen evaluaciones automáticas de respuestas, alcanzando una calidad comparable a la evaluación humana, pero con ahorros de costos que pueden alcanzar hasta el 98%. Asimismo, este sistema cubre áreas críticas de evaluación como la calidad (corrección, integralidad, fidelidad), la experiencia del usuario (utilidad, coherencia, relevancia), el cumplimiento de instrucciones (adhesión a directrices, estilo profesional), y el monitoreo de seguridad (daños, estereotipos, manejo de rechazos). La integración de esta característica con Amazon Bedrock permite a los usuarios gestionar la funcionalidad desde la consola de AWS, facilitando el uso de conjuntos de datos personalizados con fines evaluativos.
El marco «LLM-as-a-judge» proporciona una solución integral para que las organizaciones optimicen el rendimiento de sus modelos de IA, manteniendo elevados estándares de calidad y seguridad. Esta tecnología asegura que las aplicaciones de inteligencia artificial no solo operen de manera eficiente, sino que también se alineen estratégicamente con los objetivos de la empresa.









