La creciente demanda de inteligencia artificial generativa en el ámbito empresarial ha impulsado el desarrollo de diversas soluciones innovadoras. Una de las estrategias más prometedoras es el uso de modelos de lenguaje de gran tamaño preentrenados, facilitados por plataformas como Amazon Bedrock. Esta herramienta no solo permite el acceso a modelos avanzados administrados por startups de inteligencia artificial y Amazon, sino que ofrece la posibilidad de personalizarlos según las necesidades específicas de cada empresa.
La personalización de estos modelos es un aspecto crítico, ya que permite ajustar sus capacidades para tareas específicas, exigencias particulares de los negocios y formatos específicos de los datos. Este proceso se realiza a través de técnicas de ajuste fino, que requieren el entrenamiento adicional de un modelo utilizando datos cuidadosamente seleccionados y etiquetados. Sin embargo, la recopilación de estos datos relevantes es un desafío considerable, tanto en términos de cantidad como de calidad.
La generación de datos sintéticos se presenta como una solución eficaz para superar estas dificultades. Al emplear un modelo de lenguaje más grande para crear datos de entrenamiento sintéticos, las empresas pueden beneficiarse de tiempos de respuesta más cortos y una reducción significativa en la necesidad de recursos, una ventaja crucial en situaciones donde los datos disponibles son escasos.
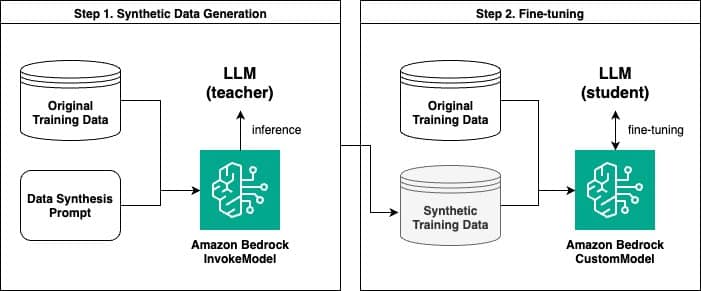
Amazon Bedrock permite a los usuarios generar datos sintéticos y afinar modelos lingüísticos basados en esta información artificial. Un estudio reciente ha ilustrado el potencial de este enfoque, detallando un proceso en dos etapas: primero, la generación de datos sintéticos a través de la API InvokeModel de Amazon Bedrock; y segundo, el ajuste fino del modelo con estos datos creados.
Este proceso genera pares de preguntas y respuestas sintéticas. Aquí, un modelo de lenguaje más grande actúa como «maestro», mientras que un modelo más pequeño aprende como «estudiante». Esta técnica, similar a la distilación del conocimiento en aprendizaje profundo, ha demostrado su eficacia en mejorar el rendimiento del modelo estudiante.
Comparaciones entre modelos ajustados con datos originales y aquellos ajustados con datos sintéticos han revelado que, en muchos casos, los modelos que utilizaron datos sintéticos lograron un rendimiento superior. No obstante, los modelos alimentados con grandes cantidades de datos originales aún mantienen su relevancia en algunos escenarios.
Para evaluar la eficacia de estos modelos, se ha implementado una metodología donde un modelo de lenguaje actúa como «juez» de la calidad de las respuestas generadas. Los resultados han mostrado que los modelos ajustados con datos sintéticos destacan en cuanto a rendimiento en comparación con sus contrapartes.
En resumen, el aprovechamiento de Amazon Bedrock para crear datos sintéticos y personalizar modelos de lenguaje representa una estrategia eficiente frente a la escasez de datos en diversas aplicaciones. A medida que las empresas continúan buscando formas más efectivas y económicas de personalizar sus modelos de lenguaje, estas innovaciones pueden desempeñar un papel crucial en sus operaciones y éxito futuro.









