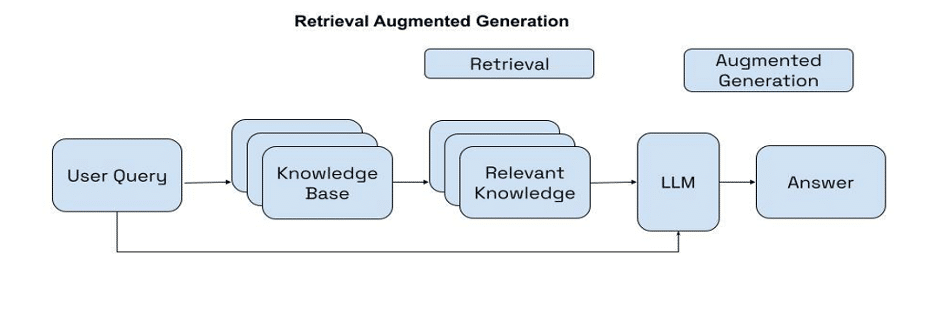
La Generación Aumentada por Recuperación (RAG) es una técnica avanzada que permite a las empresas desarrollar aplicaciones de inteligencia artificial generativa (IA) para integrar datos en tiempo real y posibilitar conversaciones más fluidas utilizando datos propios. Mediante RAG, estas aplicaciones de IA acceden a fuentes externas confiables y específicas del dominio, lo cual enriquece el contexto para el modelo de lenguaje, mejorando así la precisión y relevancia de las respuestas generadas.
Sin embargo, la eficacia de RAG depende en gran medida de encontrar las fuentes correctas de información. Es por esto que optimizar el proceso de búsqueda es fundamental para garantizar la confianza y calidad en las respuestas generadas. Aunque las herramientas RAG son esenciales para la búsqueda y recuperación de información, a menudo no cumplen las expectativas debido a pasos de recuperación subóptimos. La implementación de un paso de reordenamiento puede ser la solución para mejorar estos procesos y, por ende, la calidad de la búsqueda.
RAG combina técnicas de recuperación de información con procesamiento de lenguaje natural (NLP) para mejorar tareas de generación de texto o modelado de lenguaje. Este método obtiene información relevante de un gran corpus de datos textuales y la utiliza para optimizar la generación de respuestas. Así, se incorpora conocimiento externo o contexto adicional para aumentar la precisión, diversidad y relevancia de las respuestas generadas por el modelo.
El flujo de trabajo de la orquestación RAG generalmente sigue dos pasos:
- Recuperación: RAG extrae documentos relevantes de una fuente de datos externa usando consultas de búsqueda generadas.
- Generación fundamentada: Utiliza los documentos recuperados para crear respuestas educadas con citas en línea.
Una de las técnicas más eficaces en este proceso es la recuperación densa, que se enfoca en entender el significado semántico y la intención detrás de las consultas del usuario. Esta técnica encuentra los documentos más relevantes a una consulta en el espacio de incrustaciones, mapeando tanto las consultas del usuario como los documentos en un espacio de vectores densos.
Para mejorar la precisión, se utiliza la recuperación en dos etapas. En la primera etapa, un modelo de incrustación o recuperador extrae documentos candidatos de un conjunto de datos más amplio. En la segunda etapa, un modelo reordenador, como Cohere Rerank, evalúa y reordena estos documentos según su relevancia para la consulta. El modelo de reordenamiento genera una puntuación de similitud que ayuda a organizar los documentos en orden de relevancia.
Cohere Rerank utiliza criterios como contenido semántico, intención del usuario y relevancia contextual para reevaluar y reordenar la relevancia de los documentos recuperados. Al aplicar Cohere Rerank tras la recuperación de primera etapa, se obtienen beneficios de ambos enfoques: la recuperación inicial basada en coincidencias de proximidad en el espacio vectorial y el reordenamiento que optimiza la búsqueda para resultados más contextualmente relevantes.
La última versión de Cohere Rerank, Rerank 3, está diseñada específicamente para mejorar la búsqueda empresarial y los sistemas RAG. Rerank 3 ofrece características avanzadas, como una longitud de contexto de 4k que mejora la búsqueda en documentos más largos, capacidad para buscar sobre datos multi-aspecto y semi-estructurados, cobertura en más de 100 idiomas y mejoras en latencia y costos.
Desarrolladores y empresas pueden acceder a Rerank a través de la API hospedada de Cohere y en Amazon SageMaker. Para implementar Rerank 3 en Amazon SageMaker, es necesario suscribirse al paquete del modelo y crear un punto final para realizar inferencias en tiempo real, visualizando así los resultados de manera eficiente y precisa.
En resumen, RAG es una técnica poderosa para desarrollar aplicaciones de IA que integren datos en tiempo real, mejorando las interacciones gracias a la información contextual y propietaria. La mejora en la calidad de las fuentes recuperadas es crucial, y Cohere Rerank optimiza este proceso al evaluar y reordenar documentos en función de criterios semánticos y contextuales.









