En la era actual, donde la inteligencia artificial (IA) juega un papel crucial en diversas industrias, la técnica de Generación Aumentada por Recuperación (RAG) se ha consolidado como un elemento esencial para aumentar la precisión y la relevancia de las respuestas producidas por los modelos de lenguaje de gran escala (LLM). El éxito de RAG depende en gran medida de la calidad del contexto proporcionado al modelo lingüístico, generalmente obtenido de almacenes vectoriales en base a las consultas de los usuarios.
Una metodología eficaz para incrementar la pertinencia del contexto es el filtrado de metadatos, un proceso que permite refinar los resultados de búsqueda al realizar un pre-filtrado del almacén vectorial mediante atributos de metadatos personalizados. De este modo, se logra reducir el ruido y la información no relevante.
En escenarios que requieren consultas complejas o manejan una gran cantidad de atributos de metadatos, la creación manual de filtros de metadatos puede convertirse en un desafío considerable. Para abordar este reto, los modelos de lenguaje de gran escala pueden ser empleados en la creación de soluciones robustas a través de un enfoque identificado como filtrado inteligente de metadatos.
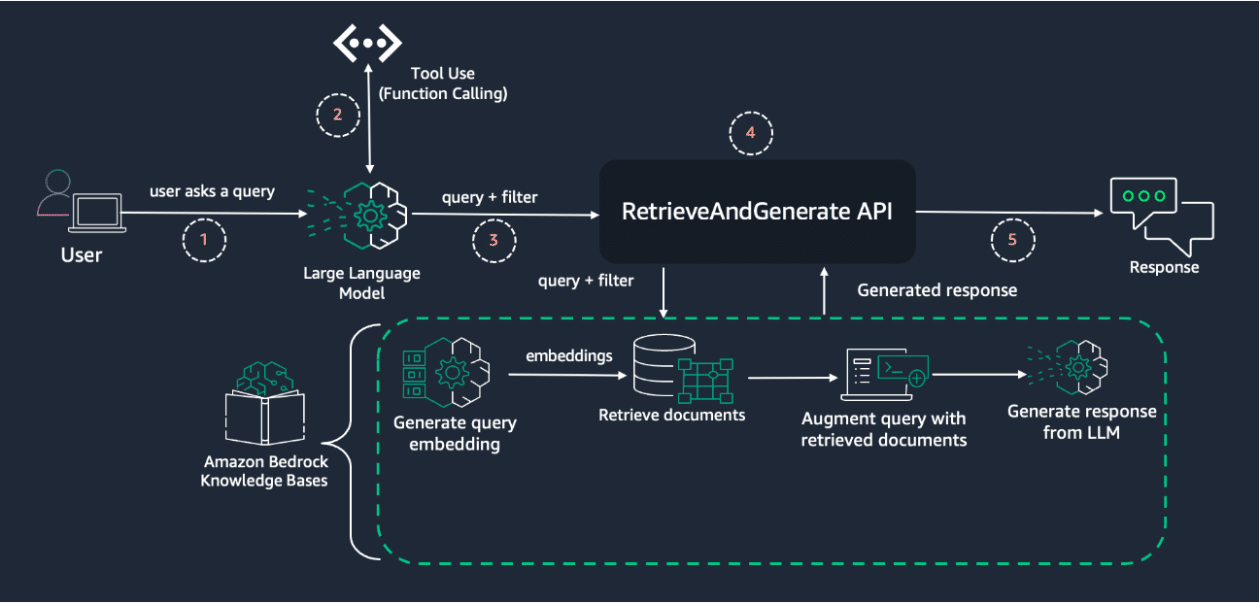
Este método ha sido implementado por Amazon mediante su servicio Bedrock. A través de este, se pueden utilizar modelos de lenguaje que extraen filtros de metadatos dinámicamente a partir de consultas en lenguaje natural, gracias a la capacidad de sus herramientas de llamado de funciones, que posibilitan la interacción de los modelos de lenguaje con funciones o herramientas externas, mejorando así su capacidad para procesar y responder a consultas complejas.
Amazon Bedrock, como servicio completamente gestionado, proporciona una selección de modelos fundacionales de alta performance desarrollados por empresas líderes en IA a través de una única API. Entre sus características destacadas se encuentran las Bases de Conocimiento de Amazon Bedrock, que ofrecen una capacidad RAG totalmente gestionada, ahora con robustas capacidades de filtrado de metadatos.
La implementación del filtrado dinámico de metadatos puede optimizar significativamente las métricas clave de un sistema RAG: la relevancia de las respuestas, el recuerdo del contexto y la precisión del contexto. La integración de Amazon Bedrock junto a modelos de datos Pydantic, empleados para la validación y estructuración de datos, permite la extracción de entidades y la estructuración de filtros de metadatos de manera que se optimice el proceso de recuperación de información.
El proceso inicia con la consulta del usuario que es procesada por un modelo de lenguaje diseñado para extraer metadatos relevantes. Estos metadatos se utilizan para construir un filtro adecuado que mejora la relevancia de los documentos recuperados del sistema de conocimiento.
El uso del filtrado inteligente de metadatos a través de Amazon Bedrock no solo simplifica el proceso de construcción de filtros, sino que también demuestra cómo es posible desarrollar aplicaciones RAG más eficientes y amigables con el usuario, posibilitando consultas en lenguaje natural más intuitivas. Así, se generan respuestas más precisas y pertinentes, alineándose mejor con las verdaderas necesidades de los usuarios.









