En la era de la inteligencia artificial, el ajuste fino multimodal se erige como un método innovador para personalizar modelos de lenguaje y visión, adaptándolos a tareas específicas que integran información visual y textual. Aunque los modelos multimodales son impresionantes en sus capacidades generales, frecuentemente no alcanzan a cubrir tareas especializadas de manera óptima. El ajuste fino, sin embargo, supera estas limitaciones adaptando los modelos a situaciones concretas, lo que mejora su desempeño significativamente en áreas críticas para las empresas.
Una aplicación clave de esta técnica es el procesamiento documental. Este proceso involucra la extracción de información estructurada de formatos complejos como facturas, órdenes de compra, formularios y diagramas técnicos. Los modelos de lenguaje de gran escala estándar suelen fallar con documentos especializados, pero con el ajuste adecuado, estos modelos pueden reconocer variaciones sutiles y aumentar la precisión mientras reducen costos.
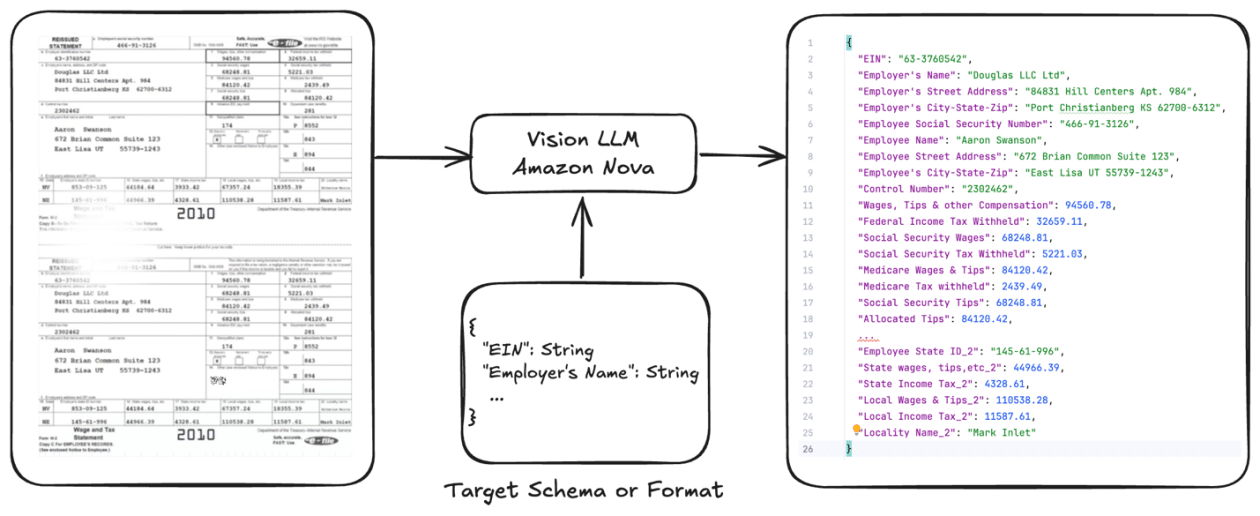
El artículo proporciona una guía exhaustiva para ajustar Amazon Nova Lite para tareas específicas, como la extracción de datos de formularios fiscales. Usando un repositorio de código abierto en GitHub, se detalla el flujo de trabajo desde la preparación de datos hasta el despliegue. A través de Amazon Bedrock, con precios por token, se logra personalizar el modelo sin comprometer la estructura de costos.
El reto principal en el procesamiento de documentos es extraer información de uno o varios documentos para uso posterior. Las empresas enfrentan diversas complejidades, como formatos variados, calidad de datos, barreras lingüísticas y exigencias críticas de precisión, especialmente en documentos fiscales.
Las estrategias para el procesamiento inteligente de documentos con modelos de lenguaje de gran escala se dividen en tres categorías: prompting sin ejemplos, prompting con ejemplos y fine-tuning. El ajuste fino es especialmente útil para personalizar modelos según tareas específicas.
Para seleccionar técnicas de personalización, se puede optar por el fine-tuning supervisado, que es ideal con datos etiquetados para tareas particulares. También es posible aplicar destilación para transferir conocimiento de un modelo grande a uno más eficiente y rápido.
La implementación en Amazon Bedrock permite a usuarios con habilidades básicas en ciencia de datos realizar ajustes completamente gestionados. Amazon SageMaker también ofrece opciones adicionales de personalización de modelos Nova.
La preparación y calidad de los datos son cruciales para el éxito del ajuste fino. Se recomienda realizar un análisis exhaustivo de los datos y alinear los prompts con las especificaciones del trabajo.
Los modelos finamente ajustados muestran mejoras significativas en precisión y métricas F1 en múltiples categorías, alcanzando una tasa de recuperación del 100%. Amazon Bedrock garantiza un modelo de costos transparente, permitiendo que las empresas escalen sus operaciones según las necesidades reales sin preocuparse por la planificación de capacidad. Esta solución se presenta como una opción eficaz y económica para optimizar la infraestructura de procesamiento documental.