En el ámbito de las aplicaciones de inteligencia artificial generativa, la velocidad de respuesta se ha convertido en una prioridad tan esencial como la misma inteligencia de los modelos utilizados. Desde los equipos de servicio al cliente que manejan consultas urgentes hasta los desarrolladores que requieren sugerencias de código en tiempo real, cada segundo de retraso, conocido como latencia, puede impactar drásticamente en la eficiencia de la operatividad. A medida que distintas empresas adoptan modelos de lenguaje de gran tamaño (LLMs) para llevar a cabo tareas críticas, surge un desafío crucial: mantener un rendimiento rápido y ágil sin sacrificar la calidad de los resultados proporcionados por estos sofisticados modelos.
La latencia ejerce una influencia decisiva sobre la experiencia del usuario, trascendiendo la frontera de ser solo una simple molestia. En las aplicaciones de inteligencia artificial interactivas, las respuestas tardías pueden interrumpir el flujo natural de la conversación, disminuir la participación de los usuarios y, en última instancia, afectar la adopción de soluciones impulsadas por inteligencia artificial. Este problema se agudiza debido a la complejidad creciente de las modernas aplicaciones de modelos de lenguaje de gran tamaño, que a menudo requieren múltiples llamados a los modelos para resolver un solo problema, incrementando así el tiempo total de procesamiento.
Durante el evento re:Invent 2024, se dio a conocer una nueva funcionalidad de inferencia optimizada para latencia en los modelos de fundación (FMs) disponibles en Amazon Bedrock. Esta nueva característica permite disminuir la latencia en el uso del modelo Claude 3.5 Haiku de Anthropic y los modelos Llama 3.1 de Meta, en comparación con sus versiones estándar. Resulta especialmente ventajosa para las cargas de trabajo donde el tiempo de respuesta es crítico para el negocio y donde cada fracción de segundo cuenta.
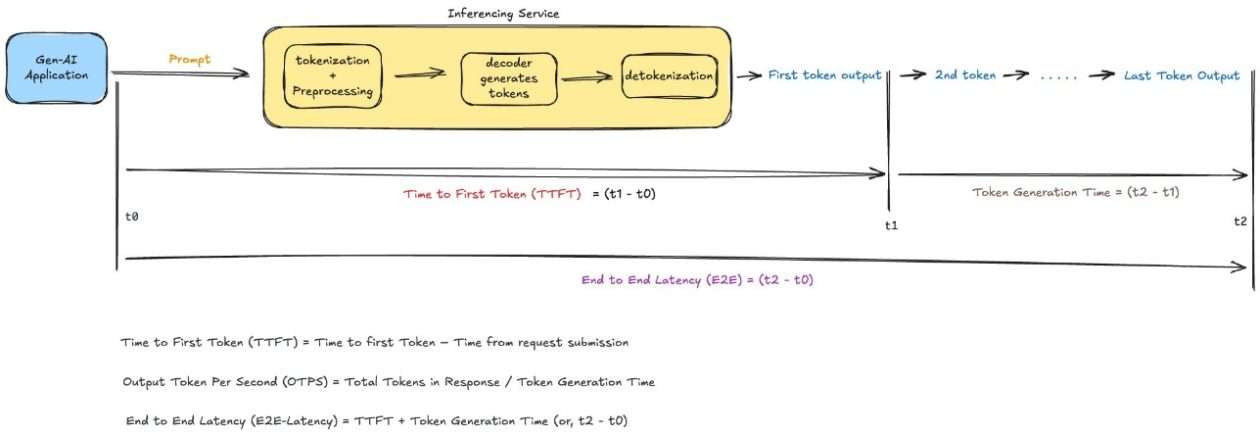
La optimización de la latencia se centra en ofrecer una experiencia mejorada a los usuarios de aplicaciones que utilizan modelos de lenguaje de gran tamaño. Aquí, la latencia se entiende como un concepto complejo que abarca aspectos como el tiempo hasta el primer token (TTFT), el cual mide la rapidez con que la aplicación comienza a responder después de recibir una consulta, además de considerar el tiempo total requerido para completar la interacción. Esta innovación responde a la creciente demanda de respuestas rápidas y precisas que no sacrifiquen la calidad, consolidándose como una solución clave en el ámbito de las tecnologías de inteligencia artificial avanzadas.









