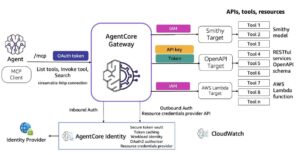
Salesforce y Amazon Web Services (AWS) han anunciado una colaboración enfocada en optimizar la implementación de modelos de inteligencia artificial, especialmente modelos de lenguaje de gran tamaño (LLMs). El equipo de Model Serving de la plataforma de inteligencia artificial de Salesforce se ha dedicado a desarrollar servicios para estos modelos, asegurando una infraestructura robusta que facilite su integración en aplicaciones críticas.
Uno de los principales desafíos que enfrenta el equipo es desplegar eficientemente los modelos, garantizando un rendimiento óptimo y una gestión de costos efectiva. Esta tarea es compleja debido a la diversidad de tamaños y requisitos de rendimiento de los modelos, que oscilan entre unos pocos gigabytes hasta 30 GB.
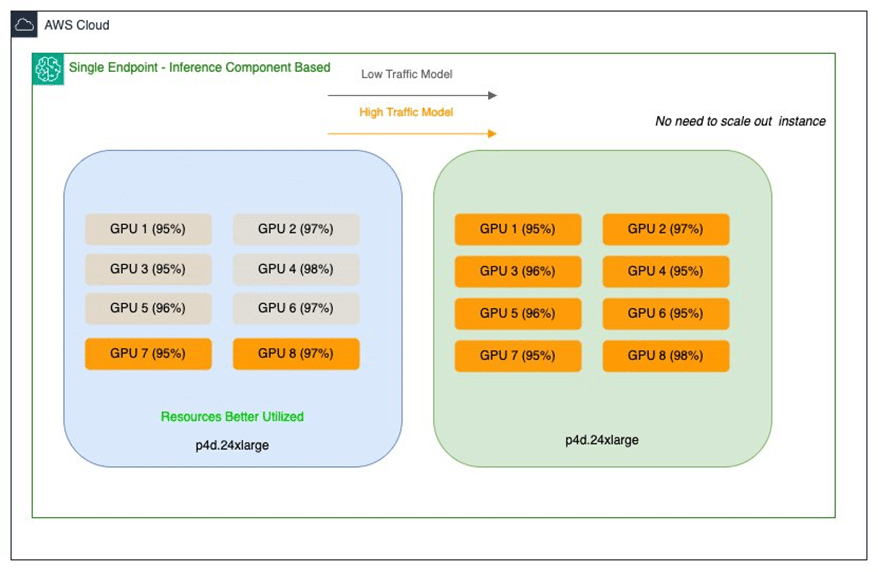
El equipo ha identificado dos retos principales. Por un lado, los modelos más grandes consumen menos recursos, lo que conduce a un uso subóptimo de las instancias de múltiples GPUs. En cambio, los modelos de tamaño intermedio necesitan un procesamiento rápido, lo que genera costos altos por la sobreasignación de recursos.
Para afrontar estos desafíos, Salesforce ha implementado componentes de inferencia de Amazon SageMaker. Esto facilita la implementación de múltiples modelos en un único endpoint de SageMaker, permitiendo un control detallado sobre los recursos, mejorando la utilización y reduciendo costos.
La estrategia de usar componentes de inferencia ofrece beneficios como la optimización del uso de GPUs y la capacidad de escalar modelos según necesidades específicas. Esta dinámica no solo resuelve problemas inmediatos de implementación, sino que también establece una base flexible para futuras iniciativas de inteligencia artificial.
Con estas soluciones, Salesforce puede disminuir significativamente los costos de infraestructura y mejorar la eficiencia operativa, logrando ahorros de hasta un 80% en costos de despliegue. Además, los modelos más pequeños también se benefician de GPUs de alto rendimiento, ofreciendo un rendimiento elevado sin incurrir en gastos excesivos.
Mirando al futuro, Salesforce planea aprovechar la capacidad de actualizaciones continuas de los componentes de inferencia, lo que les permitirá mantener sus modelos actualizados de manera más eficiente. Esto minimizará la carga operativa y potenciará la integración de innovaciones futuras en su plataforma de inteligencia artificial, posicionando a la compañía para seguir creciendo y expandiendo sus ofertas mientras mantiene estándares altos de eficiencia y efectividad en costos.