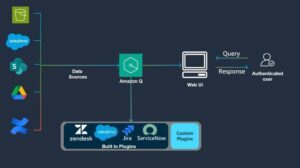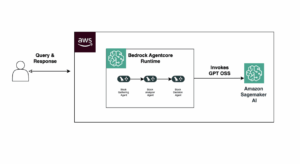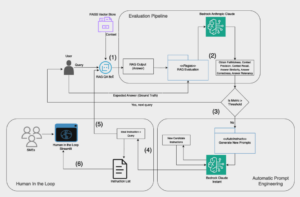
Evaluación Innovadora De Chatbots: La Plataforma De Tealium Con Ragas Y Auto-Instruct Usando AWS AI
En un esfuerzo innovador, Tealium, en colaboración con el AWS Generative AI Innovation Center, ha desarrollado un marco para evaluar y mejorar los sistemas de Generación Aumentada por Recuperación (RAG). Este avance busca optimizar las funciones de un chatbot de preguntas y respuestas que ha sido desarrollado por Tealium, reconocida por su liderazgo en la integración de datos de clientes