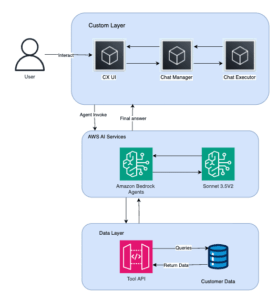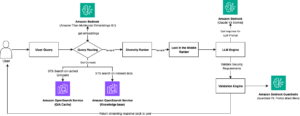
Amazon Finance Automation Lanza Asistente de Chat con IA Generativa Usando Amazon Bedrock
En un esfuerzo por optimizar el tiempo de respuesta ante consultas de clientes, Amazon ha desarrollado un asistente de chat basado en inteligencia artificial generativa en su plataforma Amazon Bedrock. Tradicionalmente, los analistas de Cuentas por Pagar y Cuentas por Cobrar de las operaciones financieras de Amazon se enfrentaban a un proceso laborioso al recibir solicitudes de clientes, ya que