Compañías vascas concluyen proyecto innovador para proteger la red eléctrica de ciberataques
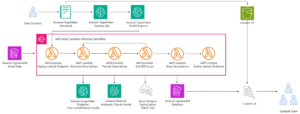
El proyecto Sec2Grid se encuentra en su etapa culminante tras haber sido desarrollado con el respaldo del programa Hazitek 2022 del Gobierno Vasco, que ha destinado una inversión de 6,4 millones de euros a esta iniciativa. Este innovador proyecto tiene como objetivo principal robustecer la ciberseguridad en el ámbito de las redes eléctricas, las cuales han ido aumentando en complejidad