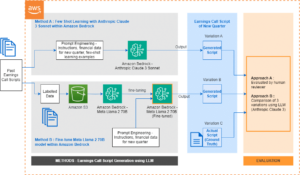
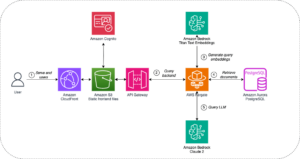
Aceleración de Modelos LLM con Decodificación Especulativa y AWS Inferentia2
En los últimos años, el tamaño de los modelos de lenguaje de grandes dimensiones (LLMs) ha aumentado considerablemente, utilizados para resolver tareas de procesamiento del lenguaje natural (NLP) como la respuesta a preguntas y la resumir texto. Los modelos más grandes, con más parámetros, que ahora están en el orden de cientos de miles de millones, tienden a producir mejores