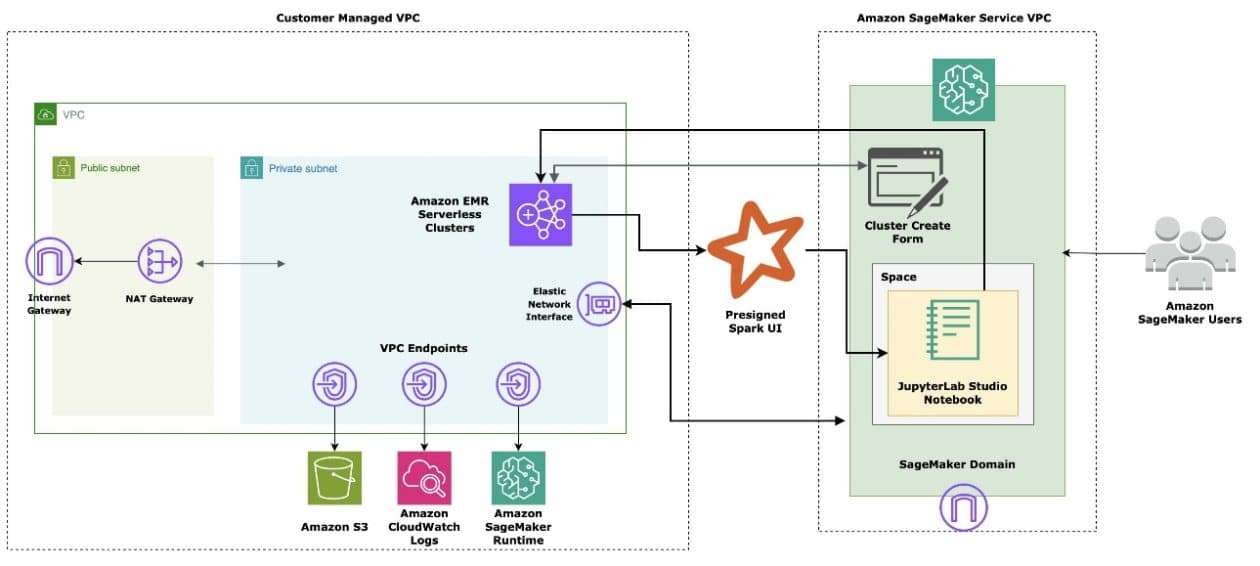
Aprovechar el poder del big data se ha vuelto fundamental para las empresas que buscan obtener una ventaja competitiva. Desde la obtención de conocimientos hasta la potenciación de aplicaciones impulsadas por inteligencia artificial generativa, la capacidad de procesar y analizar grandes conjuntos de datos de manera eficiente es una capacidad vital. Sin embargo, gestionar la compleja infraestructura necesaria para las cargas de trabajo de big data ha sido tradicionalmente un desafío significativo, a menudo requiriendo experiencia especializada. Es aquí donde la nueva integración de la aplicación Amazon EMR Serverless en Amazon SageMaker Studio puede ser de ayuda.
Con la introducción del soporte de EMR Serverless para los endpoints de Apache Livy, los usuarios de SageMaker Studio ahora pueden integrar sin problemas sus notebooks de Jupyter que utilizan núcleos sparkmagic con las potentes capacidades de procesamiento de datos de EMR Serverless. Esto permite a los usuarios de Studio realizar preparación e investigación interactivas de datos y aprendizaje automático a escala de petabytes directamente dentro de sus notebooks, sin necesidad de gestionar la infraestructura de cómputo subyacente. Además, utilizando las APIs REST de Livy, los usuarios de SageMaker Studio pueden extender sus flujos de trabajo de análisis interactivos más allá de escenarios basados en notebooks, proporcionando una experiencia de ciencia de datos más completa y optimizada dentro del ecosistema de SageMaker.
Los beneficios clave de integrar EMR Serverless con SageMaker Studio incluyen la simplificación de la gestión de infraestructura, la integración fluida con la plataforma SageMaker, la optimización de costos, la escalabilidad y el rendimiento mejorados, y la reducción de la sobrecarga operativa.
En el ámbito de la tecnología de aprendizaje automático, Amazon SageMaker Studio es un entorno de desarrollo completamente integrado que permite a los científicos de datos y desarrolladores construir, entrenar, depurar, desplegar y monitorear modelos en una única interfaz web. Studio opera dentro de una nube privada virtual gestionada por AWS, asegurando acceso a la red configurado como solo VPC.
El soporte de EMR Serverless también permite ejecutar transformaciones de datos interactivas a través de Spark utilizando interfaces de programación eficientes como PySpark, que facilitan el procesamiento distribuido de enormes volúmenes de datos. Las nuevas integraciones permiten que se gestionen clústeres de datos con menos esfuerzo manual, lo que simplifica la carga administrativa y reduce costos asociados.
En esta línea, se puede crear un motor de procesamiento de documentos basado en PySpark para sistemas de Generación Aumentada por Recuperación (RAG, por sus siglas en inglés). Este sistema permite la generación de textos con contexto, combinando metodologías de recuperación de información y generación de textos, lo que entrega resultados comprensivos y precisos. La integración de EMR Serverless con Spark y un servicio de vector de base de datos como Amazon OpenSearch, potencia la capacidad de manejar grandes volúmenes de datos textuales y generar embeddings relevantes para su posterior almacenamiento y recuperación.
Además, los procesos de autenticación en la integración de EMR Serverless con SageMaker Studio se gestionan mediante roles de ejecución de AWS Identity and Access Management (IAM). Esto permite que las cargas de trabajo accedan a recursos necesarios, como buckets de Amazon S3, amparados en los principios de los permisos mínimos necesarios, lo que mejora la seguridad general.
La actualización de políticas y roles se realiza a través de herramientas de infraestructura como código (IaC) o mediante la interfaz de línea de comandos de AWS (AWS CLI), facilitando la administración granular de usuarios y permisos en entornos de Amazon EMR y SageMaker.
La integración no solo simplifica la gestión y el uso de grandes volúmenes de datos, sino que también optimiza la eficiencia en el desarrollo de modelos de aprendizaje automático, desbloqueando nuevas posibilidades dentro del familiar entorno de SageMaker Studio.







