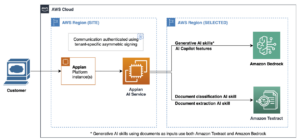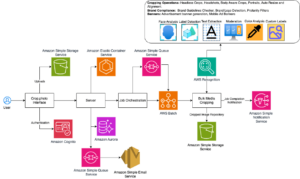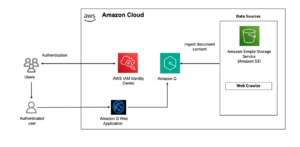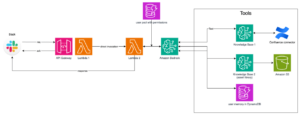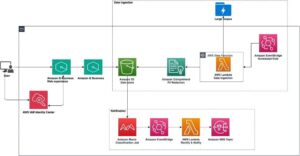
Amazon Q Business Facilita la Integración de Bases de Conocimientos Empresariales a Gran Escala
En el dinámico mundo de la inteligencia artificial, Amazon ha introducido una nueva herramienta que promete revolucionar la forma en que las empresas integran y gestionan información. Se trata de Amazon Q Business, un asistente impulsado por inteligencia artificial generativa diseñado para responder preguntas, generar contenido y llevar a cabo tareas complejas de manera segura, basándose en los datos incorporados