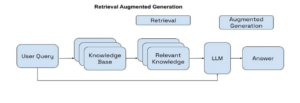
Optimiza el rendimiento de tu navegador al usar extensiones en Microsoft Edge
Microsoft ha anunciado recientemente una nueva herramienta en su navegador Edge que permitirá a los usuarios detectar el impacto que tienen las extensiones en el rendimiento de la navegación. Esta herramienta, llamada detector de rendimiento de extensiones, ayudará a los usuarios a identificar si las extensiones instaladas están provocando retrasos consistentes en la carga de las páginas web. Las extensiones